

エレクトロニクス業界の最近のブログ記事
早く買収されたい外資系の社員たち
(2020年1月28日 13:37) 1月中旬に東京ビッグサイトで開催された第12回オートモーティブワールドでは、これから買収されようとする企業の社員が早く買収されたいという声を聞き、彼らの気持ちの高まりを感じ取った。一方で、相乗効果のない事業部門でも買収提案されたら何が何でもそれを手放さない、という日本の企業経営者の姿勢との大きな差を見ることができた。

図 第12回オートモーティブワールドの一風景
ここで買収しようとしている企業がドイツのインフィニオンであり、買収されたいと社員が浮足立って期待が先走っている企業が米サイプレスだ。また、日本の企業経営者とは東芝のトップである。ガラスメーカーのHOYAが東芝の子会社で半導体製造装置を作っているニューフレアテクノロジーの買収を提案した時に示した東芝の経営者はまるで駄々っ子のようだった。
インフィニオンがサイプレスを買収するとクルマビジネスで極めて大きな効果がある。単に売上額の足し算によるものではない。互いに重なる製品はほとんどなく、しかも共にクルマ向け半導体事業に力を入れており、大きく伸びそうなことがはっきり見えるからだ。クルマメーカー(OEM)にはワンストップショッピングで製品ポートフォリオを示すことができ、それらを使ってシステムを提案できるのだ。これからの半導体ビジネスを先導するような仕掛けだといえる。
自動車産業は一番上にOEMがいて、その下にデンソーやボッシュ、コンチネンタルなどのティア1サプライヤ、その下に電子部品や半導体などのティア2サプライヤがいるという産業構造である。最近は半導体メーカーがOEMに直接、新しいシステムを提案するようになってきた。このため、開発するシステムを直接クルマメーカーに提案できることは極めて有利だ。OEMは提案内容のメリットを享受できるだけではなく、新しいハイテクをいち早く取り入れることができるからだ。かつてはBMWが、最近ではAudiが進取の気性ともいうべき新しもの好きなOEMである。
インフィニオンはパワー半導体だけではなく、レーダーやジャイロなどのセンサ半導体も持っており、ハイパワーのパワーマネジメントIC、さらにはセキュリティを担保するセキュリティマイコンにも強い。片やサイプレスはアナログ回路もプログラムできるマイコンのpSoCの評判が良くさまざまなセンサやインターフェイスIC、タッチセンサなどにも応用している。クルマでは、これからのコックピット向けにマイコンベースでグラフィックスを描画できるICや中小のパワーマネジメントICなどもある。クルマへの応用として両社の持つ全ての製品を使ったソリューション提案ができるのが最大の強みだ。このことは買収される側のサイプレスの社員が熟知しており、両社の相乗効果に大きな期待を寄せている。
ビッグサイトで開催されたこの展示会では、出展したサイプレスの社員が買収の決定をまだかまだかと待っている様子を感じ取れた。相乗効果で両社とも強くなれることをよくわかっているからだ。インフィニオンもこれでクルマ向け半導体のトップメーカーになれることで期待に胸を膨らましている。これほど相乗効果が期待できる買収も珍しい。
ところが、東芝の子会社であるニューフレアテクノロジーが買われることに東芝が断固として反対した姿勢は全く理解できない。東芝にとって相乗効果のない部門だからだ。先端半導体製造に必要な電子ビーム露光装置を設計・製造しているニューフレアは、自社内では使い道がない。他社に売るために電子ビーム露光装置を作っている。
ここにガラス製造のHOYAがニューフレアへの買収を提案した。ただ、いきなり買収提案したわけではない。HOYAは2017年からニューフレアテクノロジーとの提携話を東芝に持ち込んできていたが、肯定も否定もしない煮え切らない態度が続いていた。ところが2019年11月にいきなり東芝がニューフレアの株式をTOB(公開株式買付)で買うことを発表したため、その一月後にHOYAはニューフレアを買うためのTOBを仕掛けた。
HOYAは半導体製造に必要なガラスマスク(回路パターンを形成したガラス基板)とマスクブランクス(ガラス一面をメタルなどでマスクした基板)を製造しているが、マスクブランクスから電子ビーム露光装置で回路パターンを描く。HOYAは今、外部から電子ビーム露光装置を購入しているが、自社で装置を持っていれば、顧客からの要求で装置を改良したり発展させたりすることができる。半導体の微細化技術は最先端の7nmプロセスから、X線のように波長の短いEUVリソグラフィ技術を使うようになったが、そのマスクも電子ビーム露光装置が製造する。最先端の顧客にも対応でき、HOYAのビジネスは半導体関連分野で広がるはずだった。
東芝にとってはほとんど相乗効果がないのにもかかわらず、ニューフレアを大事に持つ意味はどこにあるだろうか。むしろHOYAは東芝が実施する株価よりも1000円も高く買うわけだから、今のうちに売却する方が良かったのではないか、と考えることはごく自然である。
これまで総合電機の経営者の姿を見てくると、自分で判断もその材料も持っていないのにもかかわらず、事業を手放さず持っていたいという気持ちが強いようだ。例えば、NECは半導体部門をNECエレクトロニクスとしてスピンオフさせたが、株式の8割以上を持っていた。親会社-子会社という関係を維持しているため、人事権も親会社が持つ。子会社が好きなように経営しても親会社が気に入らなければ子会社のトップはすぐに外へ飛ばされる。海外の優良企業の経営者ではこんな非合理なことはありえない。例えばフィリップスから独立したNXPセミコンダクターやリソグラフィのASMLなどは子会社ではなく、フィリップスの持つ株式は10%程度、現在はゼロになっている。スピンオフした以上、自分で稼ぐことが条件である。シーメンスから独立したインフィニオンも同様だ。経営者自身が理解できないビジネスは持たないことが原則だからだ。
日本ではひたすら様々な事業部を天下に収めることが経営者の仕事になっている。しかし、企業を成長させ、社員や株主がハッピーにさせることが経営者の使命ではないか。東芝はこれから10年間、どうやって成長させ社員や株主をハッピーにさせるのか、いつになったらその意志が発表されるのだろうか。
(2020/01/28)
AppleがImaginationに再びライセンス供与を受ける背景を探る
(2020年1月12日 17:08) モバイル向けGPU(グラフィックプロセッサ)をAppleが自主開発することはそう簡単ではなかった。AppleがどうやらGPUの自主開発を断念したようだ。モバイル向けのGPU回路に特化しているIPベンダーの英Imagination Technologies(イマジネーションテクノロジーズ)は、Apple社との新たなライセンス契約を結ぶことで合意した、と昨年暮れに発表した。
Appleは、2017年にGPU(グラフィックプロセッサ)を2年以内に自主開発するとImaginationに通告して、Imaginationは苦しんできた。MIPSのCPUコアを手放し、もともとのコアコンピタンスであるGPUに特化し、マネージメントも交替した。それでもImaginationはGPUの研究開発の手を緩めなかった。

図1 これは写真ではない。レイトレーシングを使った絵の例だ 出典:Imagination Technologies
グラフィックスというコンピュータ上で絵を描くための技術をさらに極めてきた。この結果、レイトレーシング(Ray Tracing)と呼ぶ技術をモバイルに応用できるIPコア(LSIの中の一部の知的回路)の開発のメドをつけた。今年後半から来年にかけて一般にリリースする予定だという。従来のグラフィックスという絵を描くだけの機能であれば、もはや参入バリヤは下がっていた。このため、AppleはGPUを自社開発できると踏んでいたようだ。しかし、グラフィックスの究極ともいうべきレイトレーシング技術はそう簡単ではない。ここにImaginationが技術開発を続けてきた意味がある。
レイトレーシング技術は、空間の中のあらゆる光の反射を含め物体に当たる光路を計算し、写真と区別のつかないような絵をコンピュータ上で描くという技術だ。物体に当たるとその色の加減も変わるようにレンダリング(色塗り)作業を変えていく。計算が極めて複雑になるため、膨大な計算量が必要となる。
最近ようやく、リアルタイムで動画を描けるようになってきた。それもNvidiaのGPU専用チップを使っての話しである。Nvidiaは2018年にリアルタイムのレイトレーシング技術のメドを付けた。今のところゲームへの応用はあるが、これまでもレイトレーシング技術は映画にも採用されてきた。10年ほど前の「ベンジャミン・バトンの数奇な運命」にもグラフィックスが使われていた。ただし、リアルタイムで絵を描けなかったため、映画製作に何カ月もかかった。
レイトレーシング技術は、グラフィックスを活用するゲーム作りには使われるのは間違いない。加えて、上記の映画作りも容易にする。本格的に普及すると、俳優、女優さんたちは失業するかもしれない。俳優さんの動作をグラフィックス上で本物と区別がつかなくなるくらい表現できるようになるからだ。もちろんクルマのデザインをはじめとする工業デザインにも入り込むだろうし、それをリアルタイムで表現できるようになると、光が当たる物体の動きをリアルタイムでとらえる物理をはじめとする科学の研究にも生かせるだろう。
ただ、NvidiaのGPUは性能が抜群に良いが、消費電力も高いためモバイルには使えない。電池があっという間に消耗してしまうからだ。モバイルで使えるようにするためには、消費電力の低さは絶対条件。その上で複雑な光の反射をいかにして計算するか、というアルゴリズムの開発にかかっている。Imaginationはこの技術にメドをつけたために、Appleが新型iPhoneへの導入にはImaginationのライセンスなしでは実現が間に合わないと判断したのであろう。Imaginationは、中国のスマホメーカーにもライセンス供与しているため、中国陣営がレイトレーシング技術を導入したAPU(アプリケーションプロセッサ)をスマホに搭載するなら、Appleは絵作りで中国に敵わなくなることは目に見えている。
Appleは、2017年にGPUの自社開発を宣言したものの、やはりうまくいかず、Imaginationからエンジニアも移動させた。すでに2年経つが、レイトレーシングという差別化技術では、やはりImaginationに敵わないとAppleは判断したのであろう。今回、AppleはImaginationに対して今後数年間を見据えた長期的なライセンス契約を結んだ。Imaginationのレイトレーシング技術は数年前にAutodeskの一部門を買収して手に入れたが、開発には7~8年かかっている。そう簡単に誰でも開発できる技術ではなさそうだ。Appleの読みは正しいかもしれない。
(2020/1/12)
医療デジタル化成功の第1歩は、差別意識の撤廃から
(2020年1月11日 14:31) バイオJapan/再生医療Japanというメディカル関係の展示会が1986年以来、21回開催され、今年はこれら二つの展示会にhealthTECH Japanという名称の展示会が追加、同時開催されることが決まった。医療関係の展示会にようやくデジタルテクノロジーが入り始める。
10年以上も前からIT/エレクトロニクスが医療の診断だけではなく治療にも使えることが明らかになって久しい。医工連携すなわち医学と工学をタイアップして治療にテクノロジーを使おう、という提案もあったが、医学系の先生は敷居が高く、工学系からの提案だけに終わっていた。筆者も10年前に医療向けの半導体チップを取材し、2010年日刊工業新聞社から刊行した「欧州ファブレス半導体産業の真実」(参考資料1)の中で紹介した、ロンドン大学インペリアルカレッジからスピンオフして設立されたトゥーマズ・テクノロジー(現在センシウム・ヘルスケア社)は、ヘルスケア半導体チップを開発するベンチャー企業だった。
この半導体チップを実装したプラスターパッチを患者の胸に貼り付け、24時間身体情報をモニターしておけるため、当初集中治療室に運ばれた患者の容態変化を即座に知ることができる上に、看護師が付きっ切りで見ている必要はない。無線で心拍数・呼吸数・体温を2分ごとに測定し続け、そのデータを病院内のサーバーに送る。最大5日まで使え、その間シャワーを浴びることもできる。早期治療ができ回復させることができるため、患者の入院日数は大きく減る。オランダの病院でこのスマートパッチの実証実験を始めた(参考資料2)。
日本でもこういった半導体チップを開発すべきだと筆者ともう一人が7~8年前に提案し、彼はスマートパッチのビジネスモデルを提案し、企画書の草案を持ってファンドや経済産業省などに説明に回ったが、見向きもされなかった。一方、日本では医療側の体制が全くできておらず、厚生労働省の許認可にも膨大な時間がかかると聞かされていた。
今ようやく、ヘルスケアにデジタルテクノロジーを導入することに賛同されるようになり始めている。healthTECH Japanを通して、デジタルメディスン、デジタルセラピューティクスの活用が始まりつつある。ただし、成功できるかどうかは、医師側、IT側を含めすべての人たちが対等・平等・自由な立場でコラボできるかどうかにかかっている。
最近のデジタル化やデジタルトランスメーション、デジタライゼーションなどの言葉は、半導体チップとIoT組み込みシステムを使ってエレクトロニクス技術でヘルスケアや医療、社会活動や生活を変えようという意味である。最近ではエレクトロニクスや半導体という言葉よりもデジタル化やデジタルトランスフォーメーションといった方が受け入れられやすい。デジタル化が進めば進むほどアナログ半導体が成長することが明確になっており、エレクトロニクス化が産業や民生を超えて社会へと進出していることを裏付けている。
テクノロジーの中身はIoTと組み込みシステムでエレクトロニクス回路を組み、ソフトウエアで変更しやすくしている。このため、デジタル化にはシステム設計をはじめ、部品、ハードウエアの設計・製造、ソフトウエア部品やアーキテクチャ、半導体設計・製造、そして医療側の要求とそのブレイクダウンなどさまざまな人たちの協力が必要になる。デジタル化を推進するためにはコラボが欠かせないのである。コラボを成功させるためには、全員が対等な立場で自由に議論し合える場が必要で、そのためには互いを尊重し合える雰囲気がなければできない。
ヘルスケアや医療の分野でもようやくデジタル化が注目されるようになった。医療のデジタル化では、健康管理から未病・予防医療、治療、予後・介護などにITエレクトロニクス・半導体を使って患者の命を救うのである。healthTECHは医療側からITエレクトロニクス側に寄ってきたといえそうな産業だといえる。
医療・ヘルスケアでテクノロジーの導入を成功させ、人の命を救うミッションを発展させるためには、医者もエンジニアも意識改革が欠かせない。両者とも互いを尊敬しあうことだ。日本でエコシステムがなかなかできないのは、上から目線、下からの忖度など互いに平等な意識に至っていないからだ。これまで製造業などでは、大企業→子会社→孫会社、あるいは大企業→下請け会社→サブ下請け会社などの構造が出来上がっていたため、みんなが平等に仕事するという意識が低く、日本ではエコシステムが出来にくかった。霞が関の官僚も民間企業に対して上から目線になる。
ヘルスケア・医療の世界では、医師側と製薬側や装置側など1対1のコラボはこれまでもあった。しかし、多数の企業が一つのゴールに向かって仕様・設計・生産・テストなどを行うエコシステムはなかった。これから、医療の知識が豊富な医師と、ITや半導体の知識が豊富なエンジニア、ソフトウエアエンジニア、システムエンジニアなどが互いを尊重しつつ共同作業をやる場合、どちらかが上ということはない。
みんな平等という意識と、互いを尊重する心は、残念ながらこれまでの日本では乏しかった。だからエコシステムは生まれにくかった。男女平等と言いつつ、賃金格差が依然として残っている。女性に責任のある仕事を任せない企業も多い。上司と部下という上下関係も残る。差別意識を減らしていく努力も足りない。外国人を翻訳・通訳としてしか使わない。多様化と言いつつ、企業の社員構成の95%以上が日本人で、その8割以上が男という古い構成の企業は圧倒的に多い。
ITエレクトロニクスの分野で外国企業が日本よりも圧倒しているのは、エコシステムの差である。ビジネスをするうえで今でも残る「どこの馬の骨かわからない相手」という上から目線。持っている技術が素晴らしければ、すぐにでも使う国々とはやはり大きく遅れている。国内では、ITエレクトロニクス産業よりももっと保守的な医療の世界でエコシステムが本当に作れるだろうか。

図1 英Sensium Healthcare社CSOのAlison Burdett氏
ヘルスケアのデジタル化を叫ぶ以上、医学界の意識改革なしで、デジタル化は進められない。さもなければ医療の世界もガラパゴス化する可能性は大いにある。冒頭で紹介した英国のトゥーマズ・テクノロジー社は医学部のクリストファー・トゥーマゾウ教授と工学部のアリソン・バーデット博士(図1)が設立したベンチャー企業である。日本でもこういった企業を誕生させることが、成功への第一歩かもしれない。
参考資料
1. 津田建二著「欧州ファブレス半導体産業の真実」、日刊工業新聞社刊、2010年11月発行
2. VieCuri Uses Sensium Vitals Patch for Remote Monitoring(2019/12/11)
大丈夫か、東芝の半導体、今は良いが将来が心配
(2020年1月 9日 21:03) 東芝の半導体部門の将来が心配だ。今はまだ、東芝の半導体は世界の競合と渡り合えている。これに甘んじて東芝経営陣は、このままでよいと思っているようだ。新しい戦略が出てこないのだ。東芝の半導体部門である、東芝デバイス&ストレージ(D&S)社の攻めの姿勢、すなわち成長戦略が提供されるのはいつになるのだろうか。また、キオクシア社からも成長戦略が見えない。東芝の経営陣はキオクシアに対して連結対象にはないものの、持ち分会社となっているため、キオクシアは、東芝から完全独立という訳ではない。

東芝デバイス&ストレージ社は、半導体部門とHDD部門の寄せ集めチームである。ストレージではない半導体デバイスとHDDとはほとんど相乗効果はない。片やキオクシアはNANDフラッシュのみの製造会社である。キオクシアは「記憶」という言葉にギリシャ語の「Axia(アクシア)」をくっつけた言葉だという。つまりメモリ会社であるというなら、なぜDRAMを生産しないのだろうか。ライバルのサムスンやSKハイニクス、マイクロンテクノロジーなどのメモリ(記憶)メーカーは全てDRAMとNANDフラッシュを持っている。このため、NANDフラッシュがダメでもDRAMで稼げる。DRAMはAIという新しい用途も見つけた。従来のコンピュータに加え、AIにもDRAMは欠かせない。キオクシアだけがNANDフラッシュしか持たない1本足打法を採る。
そもそもDRAMとNANDフラッシュでは用途が全く違う。半導体メモリという言葉で括れば、どちらもメモリであるが、特性が全く違うため、使われる用途も違う。DRAMは何度でも書き換えられるメモリでしかも書き換え速度も読出し速度も速い。ただし、電源を入れている時しか記憶しない。このため、コンピュータを動作させている時は、演算器(CPU)とセットで使う。コンピュータでは、何番地にあるデータと別の番地のデータを組み合わせて、別の番地にある命令に従って計算しなさい、という動作を行うため、CPUとメモリは近ければ近いほど性能は速くなる。
これに対して、NANDフラッシュは書き換え回数が少なく、DRAMよりも遅い。ただしDRAMよりも大容量にできるというメリットがある。しかもDRAMと違って電源を消しても記憶状態が保たれる。このため、保存すなわちストレージに向くのである。
では同じ保存(ストレージ)のデバイスであるHDD(ハードディスク装置)とは競合するのか。NANDフラッシュ、HDDそれぞれ一長一短がある。HDDに比べるとNANDフラッシュはアクセス(読み出し)が速い。しかし記憶容量はHDDの方が大きい。昔からの製造実績も豊富で、ビット当たりのコストはHDDの方が1桁も小さい。このため、性能よりも大容量やコストを重視するのであればHDD、大容量よりも性能を重視するならNANDフラッシュが使われている。NANDフラッシュはある程度HDDを置き換えてきた。しかし全てのストレージをNANDフラッシュが置き換えることはありえない。
キオクシアがストレージデバイスで成長していくのであれば、HDDを東芝D&S社に置くのではなく、キオクシアに置くべきだろう。ところが、東芝の経営陣は、HDDをNANDのライバルだと見ており、カニバリズム(自分で自分の足を食うこと)に陥ってしまうとしている。しかし、両者は食い合うのではなく、補完し合える関係にある。ビットコストの安いHDDでデータを保存するが、よく使うデータを一時記憶というキャッシュ(現金とは異なるスペルのcache)メモリとしてNANDフラッシュを使うHDDが増えている。今や多くのパソコンのHDDはNANDフラッシュをキャッシュとして使っている。このためHDD搭載のパソコンでも高速の起動が可能になってきている。現実に、Western Digital社は、HDDとNANDフラッシュの両方を持つストレージ会社である。メモリ会社ではない。
キオクシアだけがNANDフラッシュのみの1本足打法に頼るメモリメーカーである。今後に渡ってもHDD全てがNANDフラッシュに代わることはありえない。NANDフラッシュの価格が高いためだ。ストレージシステムでは、HDDよりももっとレガシーな磁気テープが今でもコールドストレージとしてデータセンターで生き残っている。HDDが全ての磁気テープを置き換えることはできない。HDDのビットコストよりも磁気テープのビットコストの方がさらに安いためだ。コストとの兼ね合いで、NANDフラッシュ、HDD、磁気テープなどがすみ分けられている。NANDフラッシュだけの1本足打法はいかにも危ない。
NANDフラッシュで東芝が成長した背景には、アップルとサムスンの争いに乗じて漁夫の利で東芝に回ってきたという幸運な面もあった。当初アップルはサムスンの製造部門にプロセッサの製造を依頼しており、NANDフラッシュもサムスン製を使っていた。しかし、両社のバトルが始まって以来、サムスンが供給していたNANDフラッシュを東芝が製造することになった。液晶ディスプレイも当初はサムスン製を使っていたが、バトルが始まり、日本のジャパンディスプレイ社に依頼するようになった。こういったラッキーな面を経営者がどれだけ理解しているかわからないが、NANDフラッシュは信頼性がそれほど高くないため、スマートフォン以外では成長の余地が大きなクルマ市場に入ることはなかなか難しい。NANDフラッシュだけに頼るリスクは将来にある。
ただ、残念ながら東芝のメモリやストレージは東芝経営陣の手に委ねられている。東芝経営陣がもっとテクノロジーを理解し、成長戦略を進めなければ停滞してしまう。利益の出ている今こそ、本気で成長戦略を練り直さなければ、東芝半導体の未来はなくなる。
(2020/01/09)
ノルウェーから来たデジタルプラットフォーマーCognite社、カギは人
(2019年12月26日 00:14) 北欧のIT企業といえば、スウェーデンの通信機器メーカーのエリクソン、自動車メーカーのボルボやサーブ、トラックメーカーのスカニアなどを思い浮かぶ。フィンランドでは通信機器メーカーのノキアの知名度が圧倒的だ。ノルウェーではファブレス半導体のノルディックセミコンダクタがすぐ浮かぶ。捕鯨漁の盛んなノルウェーに、IoTやデジタルトランスフォーメーションに欠かせないソフトウエアプラットフォームの企業、Cognite社が2016年に誕生、このほど日本にオフィスを置いた。
Cognite社はIoTシステムのデータを扱うソフトウエアプラットフォーム企業だ。IoTシステムでは、温度や湿度、振動や加速度、圧力(気圧)などのデータを拾うIoTセンサからデータを吸い上げ、ネットワークを通してクラウドに上げて、データを処理し、その結果をセンサのある現場ユーザーの元に届ける(図1)。デジタルトランスフォーメーションも実はこの仕組みが全く同じ。言葉としてIoTよりもデジタルトランスフォーメーションという言葉の方が最近はよく使われている。
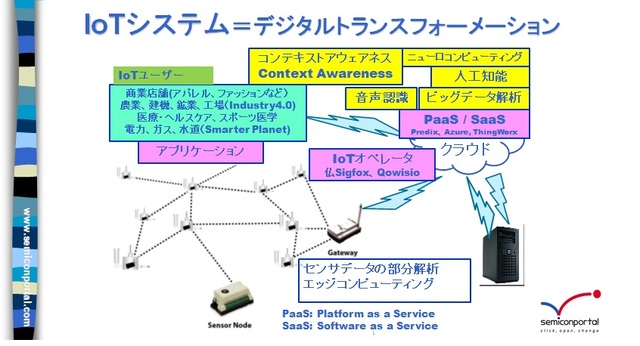
図1 IoTシステム概略図 筆者作成
ただ、一口にデータを処理するといっても、具体的にはセンサからのデータを収集し、欲しい情報との紐づけや管理を行い、保存する。その前後にさまざまなデータとの相関などを見つけるためのデータ分析を行う。センサデータはかなり重いためビッグデータとしてAIを使って解析することもあるし、多変量解析で計算することもある。さらに、データをスマートフォンやタブレット、PCなどでわかりやすい形(グラフ化)に可視化する。これらのデータ収集・管理・保存・解析・可視化、という一連の作業をソフトウエアのOS(Operating System)のように扱うのがソフトウエアプラットフォームだ。Cogniteは、このOSのようなプラットフォームを提供する会社である。
IoTシステムでは、IoTセンサを作っているメーカーやネットワークでクラウドにデータを送り出す企業、アプリケーションソフトウエアを書く企業など、さまざまな企業が協力するエコシステムがIoTシステムでは欠かせない。ソフトウエアプラットフォーム企業Cogniteも、このエコシステムの一員だ。
Cogniteがこのほど日本オフィスを開設したのは、「日本では製造業や重化学工業がしっかりしており、サービスやイノベーティブな製品で知られているからだ」と同社CEO兼創業者のJohn Markus Lervik氏(図2)は述べている。しかも日本の重工業はソフトウエアを使ってデジタル化を加速していることを知っている。実際、IHIやブリジストンなどの重工業産業は、すでにIoTシステムを使って予知保全に取り組んでいる。IHIはセンサそのものも開発している。日本市場はCognite社にとって潜在顧客が多そうだ。だからこそ、日本法人がアジア太平洋地区のリージョナルヘッドクォータとなる。

図2 Cognite社CEO兼創業者のJohn Markus Lervik氏 ノルウェー大使館にて筆者撮影
これまで、IoTのソフトウエアプラットフォーマー(デジタルプラットフォーマー)には、Predixを提供しているGEや、PTC
ThingWorx、Ayla Networksなどがいる。しかし、GE指向が強すぎたPredixや、PLM(Product Lifecycle Management)に強いPTC、民生に強いAylaと違い、Congniteは産業用のフォーカスしたプラットフォーマーである。CDF(Cognite Data Fusion)と呼ぶソフトウエアプラットフォームをクラウドベースで提供する。このため、PaaS(Platform as a Service)というビジネス提供企業である。これまでも、BP(British Petroleum)のような石油産業や製造業、電力会社などに強い。
しかも、同社の強みは何と言っても、ソフトウエアの専門家と工業(産業)の専門家からなる集団だということである。GAFAのようなインターネットサービス企業で働いていた専門家もいるという。彼らの力を結集することで、データ分析にAIも組み合わせるとしている。同社のソフトウエアプラットフォームCDFでは、データを収集し、分析することでコンテキスト(context)化する、という特長もある。コンテキスト、すなわちさまざまなデータを融合させた、これまでの文脈や履歴から次の行動を示唆し提供する。それを可視化してユーザー企業に提供する。
事例として、ノルウェーの大手石油会社のAarbakke(オールバッカー)では、コンピュータ数値制御機械の寿命をいかにして伸ばしたか、を求めたケースがある。いわばスマートファクトリである。ここではアラームが鳴った時のログを集め、エンジニアは問題個所を同定しやすくした。リアルタイムのデータとこれまでの履歴データを統合し、CDFソフトウエアで可視化する。Aarbakkeではマスターログを見ながら目標とする保守時期を決め、故障する前に故障しやすくなる時期を予知できるようになったという。これによりダウンタイムを減らし、コスト削減になったとしている。
船舶産業でも、出向する船舶の燃料や速度、運航する航路などの最適化を図り、それらをアドバイスすることでコストダウンできたとしている。最適化することで燃費は改善するようになったという。

図3 コグナイト㈱の代表取締役社長兼本社のVPとなった徳末哲一氏
日本法人を設立し、コグナイト㈱の代表取締役社長兼本社のVPとなった徳末哲一氏(図3)は、CDFのパートナー企業にはグローバルな企業が多いが、やはり日本でも同様なエコシステムが必要だと考えている。システムインテグレータやアプリケーションパートナーと手を組み、顧客となるインダストリーパートナー(石油・ガス・電力・化学・製造業)にCDF製品を使ってサービスを展開していく。その際、コグナイトと名乗っても、日本社会では簡単に受け入れられないため、大手商社と一緒に営業活動を展開するとしている。
(2019/12/26)
総合電機の経営者が殺してきた半導体ビジネス、どうなる、ソニーと東芝
(2019年12月23日 14:18) 総合電機の社長や経営陣が、ソニーとキオクシアの好調な半導体ビジネスを殺すかもしれない二つの気がかりな事件が最近現れてきた。一つは、ソニーの半導体部門を切り離すことを株主から求められ、拒否したこと。もう一つは東芝の子会社で上場しているニューフレアテクノロジーへのHOYAの買収提案を拒否したこと、である。
これまで、総合電機の経営者は、半導体部門を切り離しながらも100%子会社扱いで人事権を掌握してきた。投資が必要な時には、子会社の経営への干渉もある。この親会社の経営陣の判断ミスによって、日本の半導体産業はことごとく不振を増強し失敗の一途をたどった。ここに政府も間違った干渉をし、DRAM撤退という道を日本の全半導体部門が選んだ。唯一、1999年12月に日立製作所とNECのDRAM部門を合併させ残したエルピーダメモリでさえ、ここに親会社の経営陣が干渉し失敗させた。わずか2年で今にもつぶれる、という寸前の事態になって初めて、2002年に元Texas Instrumentsの副社長だった坂本幸雄氏を招へいした。坂本氏の元で2012年の会社更生法を申請するまで10年間事業を続けられた。ただしリーマンショックで銀行が1円も投資してくれなくなったことで万事休すとなった。
これまでの日本の総合電機という大企業の経営者は、半導体に限らず事業部門を傘下に置き、子会社扱いしてきた。子会社ということは人事権も予算権限も与えず、海外企業と競争にさらした。半導体やITはドッグイヤーと言われるほど速い経営判断が求められる。これまでの半導体部門は、設備投資のタイミングや新技術開発のタイミングなど、半導体の素人である親会社の経営陣にお伺い立てながら、根回ししながら、という時間のかかるプロセスを経なければならなかった。しかもノー、と言われれば、さらに時間をかけて根回しする必要があった。このため説得するのに時間がかかりすぎ、適切なタイミングを逃してしまった。これでは世界の半導体専業企業に負けるのは当たり前。日立、東芝、三菱などの総合電機は東京電力などの公共事業、NEC、富士通、沖電気などはNTTのような公共事業という足の長い事業にドップリと浸かっていたため、その感覚で半導体事業もついでにやっていたからだ。
今の東芝もソニーも似ていないか。東芝の子会社であるニューフレアは電子ビーム露光装置というフォトマスク製造に欠かせない装置を作っており、ArFレーザーリソグラフィからEUVに移っても電子ビーム露光装置は必要な装置である。だからこそ、HOYAのようなマスクメーカーは電子ビーム露光装置が欲しい。石英ガラスに遮光層を全面に覆っているマスクブランクス、電子ビーム露光装置でパターンを描くフォトマスクも製造・供給しているHOYAは、電子ビーム露光装置も自社製を持っていれば、顧客の要求にもすぐに対応できる。

図1 東芝の車谷暢昭会長
このためHOYAは、ニューフレアの親会社である東芝に2017年ころから複数回提携の話を持ち掛けてきた。しかし、東芝は肯定しないばかりか、今年になってニューフレアの株を市場から買い戻そうとし始めた。そこでHOYAはニューフレアの買収提案を行った。東芝は、あまり相乗効果のない子会社ニューフレアの買収案を蹴った。12月20日の日本経済新聞の記事においても、東芝の車谷暢昭会長(図1)は、「HOYAの提案に応じない」と述べている。
製品ポートフォリオを見る限り、HOYAの要求は理にかなっているが、東芝の反論は合理性がない。昔ながらの子会社を支配したがる総合電機のダメ経営者の姿とダブって見える。
ソニーも似たようなものだ。親会社はゲーム機、テレビやスマートフォンなどのエレクトロニクス商品はあるが、半導体事業の主力製品であるCMOSイメージセンサとは相乗効果がほとんどない。ソニーの株主であるファンドから半導体事業を切り離せ、という要求を受けているが、ソニーの経営陣は嫌がっている。
CMOSイメージセンサはこれまで、AppleやAndroid系のスマートフォンに大量に使われてきた。今年はスマホ市場が飽和しても、1台に2眼カメラが3眼になり、CMOSセンサはその分だけ成長してきた。特に新製品は3眼へと移行している。これによってビジネスは二けたのプラス成長になった。今後の戦略に対してもソニー半導体の経営陣は、クルマや産業向けのマシンビジョンやイメージング技術にCMOSセンサの市場拡大を期待している。
最近は特にAIとイメージセンサの組み合わせによって、人間がチェックしなければならなかった外観検査も自動化できるようになってきた。食品や薬品産業への応用が広がり、CMOSイメージセンサは今後も用途拡大に動ける。IR(赤外線)分析装置が手のひらサイズになり、例えば税関検査ではモバイルで麻薬や不法物質を簡単に検査できるようになる可能性がある。CMOSセンサは用途が広い。それでもソニーの現製品ポートフォリオとはなじみが薄い。ソニー本体が、CMOSイメージセンサの娯楽部門、金融部門での今後の応用を見つけられるのであれば、半導体をつなぎとめる意義はあるが、それがない限り親会社が支配することには無理がある。
なぜ半導体部門を離すべきか。筆者はこれまでH-Pから分離したAgilentから独立・誕生したばかりのAvago(現在世界トップテン圏内に常駐しているBroadcom)をたまたま米国出張で訪問した経験がある。その時に対応してくれた課長・部長クラスの人たちの、自分で決められることへの喜びと責任に対する気持ちの高ぶりを手に取るように感じ取った。Motorolaから独立したFreescaleを訪問した時も、同様な反応だった。半導体事業を自分の責任で、自分で決められることへの喜びそのものだった。
欧州でも、ドイツのSiemensから独立したInfineon、オランダのPhilipsから独立したNXPやASML。いずれの企業にも親会社の株式は、独立当初でさえ10%程度しかなく、子会社から外れた。いずれも大成功して世界の半導体メーカーの仲間入りをしている。世界の半導体業界では、半導体の専業メーカーが圧倒的に多い。親会社がセットメーカーでもある企業はSamsungだけになっている。韓国企業は日本と似たようなビジネスマインドを持つため、Samsungでさえ今は好調だが、この先はどうなることやら。
(2019/12/23)
2020 Robert Noyce賞を香山晋氏が受賞
(2019年12月13日 00:08) 長年、半導体業界で功績のあった人に毎年贈られるIEEE Robert Noyce賞2020が、元東芝で半導体事業を率いた香山晋氏(写真)に決まった。Robert
Noyce賞とは、世界半導体メーカートップであるIntel社の創業者の一人で、社長兼CEOも務めたRobert Noyce氏の業績をたたえ、IntelがIEEEと共同で創設した賞である。

写真 半導体産業に貢献したとしてRobert Noyce賞を受賞した香山晋氏 筆者撮影
受賞理由は次の通り:CMOS技術の開発に世界的な経営者としてリーダーシップを発揮し、設計手法の標準化に貢献、そして半導体産業に大きなインパクトを与えたことである。Robert Noyce賞は2000年から始まり、2020年に香山氏が受賞することで世界の半導体人21人目になる。ちなみに、日本人では2018年に元日立製作所の専務取締役だった牧本次生氏、2016年に東京大学名誉教授の菅野卓雄氏が受賞している。その前は2006年の元ニコン社長の吉田正一郎氏まで遡る。2002年に東芝からHewlett-Packard、そしてTexas Instrumentsを経てStanford大学の教授になった西義雄氏、2001年に元NEC副会長の佐々木元氏がそれぞれ受賞している。
香山氏は東芝時代に当時先駆的だった高集積CMOS SRAMを開発、その後ASICの設計にも貢献しただけではなく、先日、東大教授を退官した桜井貴康氏や鳥海明氏、慶応大学から東大の教授に転身した黒田忠弘氏、現東大教授の高木信一氏などが東芝にいたころ、彼らを率い、日本半導体の頭脳に育てたコーチでもある。
極めてアタマの切れる人であるため、出る杭は打たれ、東芝から追い出され、子会社であった東芝セラミックスの社長になった。大手半導体製造装置メーカーのある人は香山氏の講演を聴いて「すごいアタマの持ち主なので、とても僕にはついていけない」と筆者に漏らしたほどだ。東芝セラミックスは、その後、MBO(経営陣によるバイアウト)によって、東芝から完全独立しコバレント・マテリアルと社名を変えた。コバレントとは、結晶の共有結合を意味する言葉である。シリコン結晶を示唆することは言うまでもない。
コバレントを引退後、現在は、K. Associates社というコンサルティング会社を運営しているほか、英語が堪能なのでいくつかの米国企業の役員も兼ねている。東芝時代、半導体のオリンピックといわれるISSCC(国際半導体回路会議)で香山氏の講演を会場の一番奥で聴いた、筆者の知り合いの記者は、また米国人の発表か、と最初に思ったという。しかし、よくよく目を凝らして講演者を見ると取材したことのある香山氏だった、とその記者は筆者に漏らし、「英語がネイティブ並みだったので間違えてしまった」と語った。
Robert Noyce氏は、Intelを創業する前にいたFairchild Semiconductorで半導体のプレーナ技術を開発し、集積回路の特許を持っていたが、1990年に62歳という若さでこの世を去った。同じころ基板上に複数のシリコンチップを集積するICを発明したTIのJack Kilby氏はノーベル賞を受賞したが、残念ながらNoyce氏はもはやこの世にいなかったためノーベル賞を受け取ることはできなかった。
Intelは、Noyce氏の元でマイクロプロセッサとメモリを発明し、パソコンからインターネット、そして現在のデジタルトランスメーションの基礎を築いた。そのNoyce氏は半導体チップの現在の基礎を作った人であり、その人をたたえたRobert Noyce賞は、価値のある賞である。この賞を香山晋氏が受賞したことは、半導体産業を長年取材してきた筆者にとっても誇りに思う。
12月12日のセミコンジャパンでは、若手エンジニアのパネルディスカッションが開かれ、半導体産業に従事する若手エンジニアの仕事に対するひた向きさ、真摯な態度で、仕事を通した生き方を議論していた。彼らのディスカッションを聞いていると、日本もまんざらではないな、とすがすがしい気持ちになった。熱心な若手エンジニアを生かすも殺すも経営者の責任である。日本の半導体製造装置や半導体材料企業は、今でも世界に通用する。市場シェアも35~45%ある。やはり半導体のようなタイムツーマーケットの短い産業は、専業メーカーが強いのは世界の流れだ。彼ら若手エンジニアの中から、将来のRobert Noyce賞を受賞する人が現れることを期待したい。
(2019/12/13)
半導体事業を捨てたパナソニック、どこへ行く?
(2019年12月 3日 22:25) 先週末、パナソニックが半導体事業を全て、台湾の半導体メーカーWindbond
Electronicsの子会社であるNuvoton Technology社に売却すると発表した。このニュースは半導体業界に衝撃を与えた。GoogleやFacebook、AmazonなどのITサービス業者が自分の半導体チップを作る時代になったというのに、わざわざ手放すのである。

メモリのような大量生産できる半導体チップは、設計と製造が一体化した工場で作る方が効率は良い。しかし、数量が少ない半導体チップはファブレスとファウンドリに分けて生産する方が向いている。世界の半導体業界では、1980年代終わりころからシリコンバレーを中心に雨後の竹の子のようにファブレスが登場した。そのファブレス半導体メーカーの先駆けがザイリンクス社で、ファウンドリの先駆けが台湾のTSMC社だった。TSMC社は何十・何百社のシリコンウェーハを製造した。それぞれの生産規模が小さくてもたくさん作るからビジネスとして成り立った。
対して日本の半導体はメモリからASICや少量多品種へ事業を転換したために工場の生産能力を満たすことができなくなっていた。工場のキャパシティが埋まらないのであれば、工場を小さくするか、手放すか(ファブレス)、あるいは他の企業の注文も取るか(ファウンドリ)、の選択肢があったはずだ。しかし日本の半導体メーカーは、何も選択せず、改良しようともしなかった。たまに他社から注文を受けて生産して上げたこともあった。これをファウンドリビジネスと称したが、これも間違いだった。注文を待つだけのお店と同じだったからだ。積極的なファウンドリ営業を全くしてこなかった。このままズルズルと90年代を過ぎ2000年代を過ぎた。不作為の10年から20年が経過した。
その間、国家プロジェクトを何度も繰り返したが、全て失敗した。なぜか。工場をどうするという議論ではなく、先端技術の開発、という頓珍漢な研究テーマしか採用してこなかったためだ。霞が関にとっては国家プロジェクトという天下り先ができたために何度失敗しても、この甘い蜜に群がった。その評価は失敗ではなく成功として自己を正当化した。
日本の半導体メーカーが弱体化したのは、世界の半導体業界の動きを見ず、ひたすらガラパゴス化の道を歩んだからだ。2010年代に入ってもやはり垂直統合の方が日本には合っているという声も強かった。今回のパナソニックも何周遅れがわからないほどだが、本質的にファブレスとファウンドリという考えを検討することなく、設計部隊も製造部隊も身売りすることになった。
半導体を成長させる術を知らなかった
かつて世界最先端の工場と言われた富山県の魚津工場と砺波工場、新潟の新井工場の3工場がわずか270億円で買いたたかれた。結論を言えば、半導体ビジネスの本質を理解することなく、産業を分析することなく、企業を分析することなく、リストラしたのである。もちろん、パナソニックに限ったことではないが、他の国内半導体メーカーと比べると、パナソニックはさらに何周も遅れている。
パナソニックの前身である松下電器産業の創業者である松下幸之助氏は、日本の家庭に電化製品がまだ入っていなかった当時に、全ての家庭に水道を引くように電化製品を供給するという水道哲学を持っていた。今は全ての家庭に電化製品がある。では、パナソニックはどのような道を選ぶのか。1~2年前は産業用製品や車載製品へのシフトを打ち出してはいた。しかし、相変わらず家電製品に力を入れているように見える。全ての家庭が電化製品で満ち溢れているにもかかわらずだ。
日本市場はもはや縮小していく一方となっている。人口や働き手を増やすことを政府が打ち出していないからだ。人口は減少し、市場も減少する。この状況でも、パナソニックは国内消費者向けの製品から抜け出すことができない。では、どのようにして未来を切り開くのか。このビジョンがさっぱり見えないのである。
かつてのパナソニックは、ソニーが新製品を出した後2年くらい遅れて新製品を出し大量生産によって市場シェアを広げていった。マネシタ電器と言われてもこの路線を貫いた。今年、ソニーは国内トップの半導体メーカーになることは間違いない。2位のキオクシア(旧東芝メモリ)に大きな差をつけているからだ。世界の半導体市場は今年12.8%減という2桁のマイナス成長なのに、ソニーは18.3%増と2桁プラス成長の1兆400億円を見込んでいる。ソニーのモノづくりの中で半導体部門だけが大きな2桁の伸びを示し、さらに2桁の営業利益率を示している。FAAMG(ファーングと発音;Facebook, Amazon, Apple, Microsoft, Google; 米国ではGAFAとは言わない)といわれるITサービス企業だけではなく今や、エリクソンやノキア、華為、HPEといった通信ネットワーク機器メーカーまでも自前の半導体チップで差別化を図る時代になった。
片やパナソニックは何を成長のエンジンとしようとしているのか、全く見えない。もはや大量生産はできない時代であり、家電製品が飽和した時代である。人口増加も期待できない時代である。これまでの10年以上、パナソニックはひたすらリストラを続けてきた。リストラに疲れて成長を忘れていないだろうか。パナソニックは何を捨て、何を成長させるのか、選択と集中をもっと明確に実行しなければ本当に成長できなくなってしまう恐れがある。
(2019/12/03)
東北大、新産業起こしを本格的に開始
(2019年11月24日 11:07)寄稿
東北大学は既存の青葉山キャンパス(仙台市青葉区荒巻字青葉)の西側に広大な新青葉山キャンパスを現在、整備中だ。そして「新青葉山キャンパスを"グローバル・イノベーション・キャンパス"にするという目標を基に強力な産学連携体制を推進している」(大野英男東北大総長、図1)という。

図1 大野英男東北大学総長
大学がビジネスを仲介
このグローバル・イノベーション・キャンパス(注1)を目指す組織的な産学連携では「B-U-B(Business-University-Business)という研究大学を中核・仲立ちとした異分野の企業群が組織連携する連携モデルを実践する」と、東北大の青木孝文理事・副学長(企画戦略総括・プロボスト、図2)は説明する。

図2 青木孝文理事・副学長(企画戦略総括・プロボスト担当)
このB-U-Bモデルは、10月29日に、東京都千代田区内で開催された「東北大学オープンイノベーション戦略機構シンポジウム2019」の中で概要が公表されたもの。青木理事・副学長は、オープンイノベーション戦略機構長を務めている。
モデルは半導体研究のCIES
このB-U-Bが目指すイノベーション創出を図る組織的連携の原型になったのは「新青葉山キャンパス内にいち早く設けられた先進的な半導体チップの国際研究開発拠点である国際集積エレクトロニクス研究開発センター(CIES)である」と青木理事・副学長はいう。このCIESは、遠藤哲郎教授がセンター長を務め、AI(人工知能)・IOT(モノのインターネット技術)に向けた極限の低電力半導体チップの開発などを目指す国際研究開発拠点だ。
このCIES は、2013年に新青葉山キャンパス内にいち早く研究開発拠点を竣工し、2016年にIT・輸送システム融合型エレクトロニクス技術の創出を目指すOPERA(Program on Open Innovation Platform with Enterprises, Research Institute and Academia)プロジェクトをJST(科学技術振興機構)から委託されたことから、外部資金によって研究開発拠点を運営する仕組みができ上がった。
詳細は公表されていないが、このCIESは大まかには企業などの外部組織からの30億円の寄付や文部科学省系や経済産業省系の大学・企業の大型共同研究プロジェクトなどからの運営資金などによって、研究開発拠点棟を整備し、これまでに300億円超の先端研究開発設備を整え、1年間当たり約15億円の外部資金による運営費を確保しているとみられている。
こうした先端的な研究開発環境が整備された結果、具体的な社名は公表されていないが、日本の半導体製造企業やその製造装置・機器企業、半導体材料企業などがそれぞれ参加し、さらに米国などの半導体関連企業などの海外企業も参加している模様だ。この結果、CIESはグローバル対応の共同研究契約・知財管理態勢を整え、「集積エレクトロニクス分野での川上から川下までの企業群が国際的な産学連携コンソーシアムを構築している」という。
マテリアルサイエンスがB-U-Bを実施
このCIESで学んだ産学連携コンソーシアムの運営法などを基に、東北大はライフサイエンス分野やマテリアルサイエンス分野でもオープンイノベーション態勢を構築しつつあると、青木理事・副学長は説明する。
このマテリアルサイエンス分野のB-U-B組織連携のさきがけとして、東北大は2018年9月5日に非鉄金属大手のJX金属と組織的連携協定を提携している。この組織的連携は、JX金属が2018年6月に東北大発ベンチャー企業のマテリアル・コンセプト(仙台市)に出資し、半導体の次世代配線材料技術分野での組織的産学連携を始めたことが契機になっている。この組織的産学連携では、当面は銅系の半導体の配線材料の最適化・高性能化を目指し、さらにその先にある新しい"ネクスト銅"金属材料系の半導体の配線材料も研究開発し。実用化するというシナリオを描き、研究開発と事業化の活動を進めている。
この東北大発ベンチャー企業のマテリアル・コンセプトは、東北大大学院工学研究科の小池淳一教授の研究成果を基に、2013年4月に設立された企業だ。同社は、東北大のインキュベーション施設内に入居し、代表取締役の小池美穂氏の下で、銅系の半導体の配線材料の事業化を進めている。小池教授は同社のCTO(最高技術責任者)取締役を務めている。
同社は2014年3月4日に産業革新機構(INCJ、東京都千代田区)が第三者割当増資として6億円を上限とする3億円(推定)を出資したこと契機に、銅系配線材料の開発や事業化の事業資金を得て船出した(注2)。
JX金属は東北大の青葉山新キャンパス内に半導体の配線材料研究棟を建設し、2020年6月をメドに東北大に寄贈する計画を進めている(図3)。建設総額は10億円の見込みで、4階建て、総延べ床面積は約4000平方メートルの建屋の計画だ。JX金属としては、同研究棟が、東北大を中核にベンチャー企業を含む国内外の企業や研究機関などの産学官が結集し、次世代配線材料技術分野でのイノベーションを創出するインターコネクト・アドバンストテクノロジーセンター(ICAT)として、革新材料技術や非鉄産業関連の産学官連携拠点となることを目指している。

図3 次世代配線材料技術分野でのイノベーションを創出するインターコネクト・アドバンストテクノロジーセンター(ICAT)の模式図 出典:JX金属
JX金属が東北大と組織的連携協定を結んだ背景には「青葉山新キャンパスには世界的な半導体の研究拠点である国際集積エレクトロニクス研究開発センターなどがあり、さまざまな情報交換、人材交流が見込める点を高く評価したからだ」と説明する。
さらに、東北大の新青葉山キャンパス内では、次世代放射光施設の建設が始まり、"官民地域パートナーシップ"に基づく整備を始めている。2023年の運用開始を目標に、次世代放射光本体の開発などを進めている。
技術ジャーナリスト 丸山 正明
注1)東北大が設けたオープンイノベーション戦略機構は、2018年9月に文部科学省が始めたオープンイノベーション機構の整備事業に採択されたことを契機に設けた戦略的組織である。2018年12月から活動を始めている。文科省のオープンイノベーション機構の整備事業には、これまでに8大学が採択されている。
注2)この時のINCJの出資は、ベンチャーキャピタルの大和企業投資(東京都千代田区)との協調投資として実行された
機械学習のセッションができたISSCC2020
(2019年11月20日 10:10) 半導体集積回路(IC)のオリンピックといわれ、半導体トップエンジニアが集うIEEE(ITエレクトロニクスに係る国際エンジニアが集まる学会)主催のISSCC(International Solid-State Circuits
Conference)(図1)。ここにもAIの大部分を占める機械学習を集めたセッションができた。もはやAIは、一時のブームではなくなった。ソフトバンクグループ会長の孫正義氏は、「AIによって全ての産業を再定義する」、と述べている。例えば農業にAIを適用して生産性を向上し、グローバル競争力を向上させるなど、あらゆる産業にAIを使って全く新しい手法で生産性を大きく飛躍させるのである。

図1 ISSCCの日本における委員たちと極東地区のチェアたち
2020年2月に米国サンフランシスコで開催されるISSCCにおける11のサブコミッティ(分科会)に機械学習を追加して合計12のサブコミッティを設けることになった。その理由は、機械学習の利用や工夫などがこれまでいろいろなセッションで登場し始め、各セッションの査読委員は機械学習の専門家ではない場合が多かったために正しい評価法を見直したためだ。やはり、機械学習は一つの分科会として論文査読する方が理にかなっている。もはや一時のブームに終わるものではないことがはっきりしてきたからだ。
ちなみに機械学習の投稿論文数は25件あり、そのうち7件が採択され、採択率は28%となった。機械学習のセッションは二つ設けられ、セッション7では高性能機械学習、セッション14では低消費電力の機械学習、となっている。さらに機械学習で特長的なのは、アジアからの発表が多いことだ。セッション7では日本1件、韓国1件、台湾1件、北米1件だが、セッション14では中国が3件も採択された。中国の3件は低消費電力狙いであることからスマートフォンやモバイルデバイス用のCNN(畳み込みニューラルネットワーク)などが多い。
セッション7では、台湾MediaTekが7nmプロセスに向け5Gスマホに使うためのCNN推論デュアルコアで、データ再利用や重みの圧縮、非対称量子化などにより大幅に効率を上げ3.4~13.3TOPS/Wの性能を実現した。北米の1件はアリババの北米拠点と中国拠点との共同開発した、データセンター向けのCNN推論アクセラレータチップで、その性能はこれまで最高の825TOPSと極めて高い。韓国KAISTからの発表は、教師無し機械学習として注目されているGAN(敵対的生成ネットワーク)向けのプロセッサである。日本からの発表は、東京工業大学本村真人教授グループと日立北大ラボ、北海道大学との共同による最適化問題を解くデジタルアニーリングのエンジンである。機械学習というよりも量子アニーリングに近い。
セッション14での中国からの論文では、東南大学が量子化ビット数を極限まで減らして消費電力を下げた、1ビットのバイナリ型CNNチップで、回路をしきい値付近で動作させることによって510nWという超低消費電力動作を実現した。学会のためのチップのようなややトリッキーな感じのする論文だ。
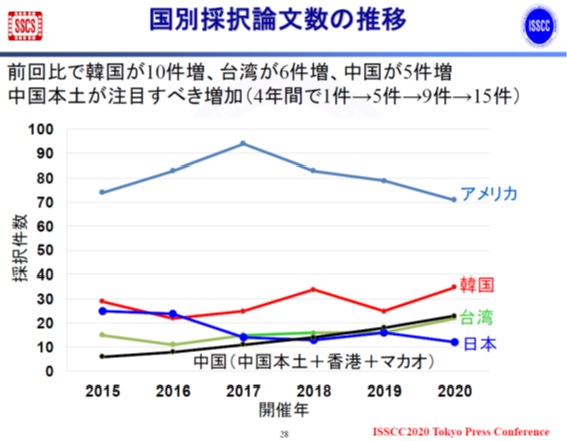
図2 日本からの発表は過去最低の12件 出典:IEEE ISSCCコミッティー
今回のISSCC全体で見た時の特長は、アジアからの採択論文が48%と多くなってきたことだ(図1)。北米が36%、欧州が16%となっている。4年前の2016年はアジア34%、北米42%、欧州24%だったから、アジアのプレゼンスが上がってきたと言えそうだ。今回は、北米の大学からの論文が49件しかなかったが、ここまで減少した理由はまだわかっていないという。
日本からの発表では、企業からの発表が10件と昨年より少し増えたが、大学の発表が前回の7件から2件へと大きく落とした。ただ、これでも企業からの発表は少なく、2015年の15件、2016年の19件からは大きく減少した。日本が今回合計で12件という数字はここ20年で最低ではないだろうか。
そもそも半導体製品を販売している地域を表すWSTSの市場統計では、世界の半導体がどこでも成長しているのに、日本だけが成長していないという事実がある(図3)。これはシステムを差別化するために使う半導体チップが活用されていないことを意味する。まさに今日本の弱さが出ているといえる。
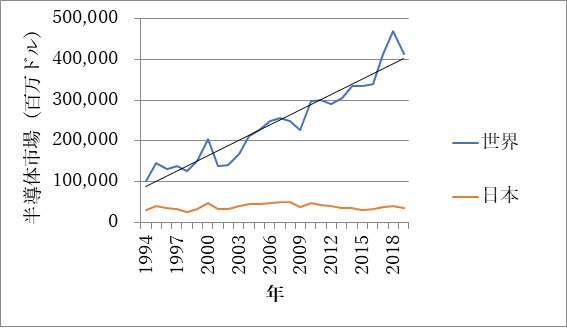
図3 半導体は世界では成長するが、日本だけが成長しない ここでの半導体市場とは、半導体チップをメーカーからユーザーへ手渡した場所を指す 出典: WSTSのデータをベースに津田建二が加工
これまで総合電機の経営者たちは、半導体事業が悪いから企業の業績が悪化したと半導体事業のせいにしてきたが、半導体を切り離しリーマン後になって電機そのものの悪さにやっと気がついてリストラ始めたが、時すでに遅し、世界から大きく離されてしまっていた。半導体ビジネスはメモリのような大量生産品以外はみんなファブレスとファウンドリに分かれたのにもかかわらず、長い間電機の経営者も半導体の経営者もそのことを認めようとせず、結局、泥沼に沈み込んだままになってしまった。
ところが、今回のISSCCで基調講演を行うグーグルのシニアフェローであるJeff Dean氏は何と半導体設計の話しをする。グーグルは自分でLSI設計言語を勉強して設計できる体制を作っており、しかも逆にディープラーニングを利用して半導体を設計するというのだ。もはやグーグルは半導体メーカーになったといえよう。
日本の電機やITの経営者が半導体チップの重要性(これこそがシステムを差別化できるカギを握るモノという本質)を理解するのはいつの日だろうか。この日が来ない限り、日本の復活はないと断言してもよいだろう。今や半導体チップはソフトウエアを埋め込んだハードウエアになっていることも重要なポイントだ。財務の専門家はリストラをできても成長戦略を作れない。財務の銀行屋が半導体のトップにいる限り、半導体部門の成長は望めないと言えるだろう。
(2019/11/20)