

エレクトロニクス業界の最近のブログ記事
エヌビディアCEO、ジェンスン・フアン氏が見る日本の姿
(2024年11月24日 10:12)今、世界の全ての企業で、企業の価値を示す時価総額が最も高い企業はどこか。もはやグーグルやアマゾン、アップル、メタ(フェイスブック)、マイクロソフトを示すGAFAMではない。ファブレス半導体企業のエヌビディア(Nvidia)である。2024年の6月にも一時的にトップに立ったが、その後株価を少し下げ、3位にしばらくいた。その時にエヌビディアは一瞬の幻想なのか、という評価があった。しかし、AIと半導体という二つの成長産業を持つエヌビディアは、再び首位に立った。実際、時価総額トップ100社のうち、半導体企業は製造装置も含め、8社も入っているが、日本企業はわずかトヨタ自動車のみである。
そのエヌビディアが11月中旬、Nvidia AI Summit 2024を東京・芝公園のプリンスパークタワー東京で開催した。Nvidia AI Summitは、米国を皮切りにインド、そして東京とやってきた。今年のテーマは、日本であった。日本が強い分野にAIを導入することによって、AIの産業をもっと強くしよう、というメッセージをNvidiaのCEOであるジェンスン・フアン氏(図1)が述べている。

図1 来日したエヌビディアCEOのジェンスン・フアン氏 撮影筆者
筆者はNvidiaのイベントをこれまで常に注目してきた。AI(人工知能)に大きく舵を切った2016年だったと思うが、Nvidiaはこれまでのゲーム機用のグラフィック・プロセッサ(GPU)からAI宣言をした。TensorFlowやPythonなどAIライブラリを使ってみたり、日本のAI企業であるプリファード・ネットワークス社とコラボしたりするなど、AI一色の企業に変身していた。
あれから10年近くになりAIが定着、その間、生成AIも登場した。ただ、AIソフトウエアで後進国の日本が今後逆転するためには、どうすればよいか。幸い、AIは始まったばかりだ。しかも日本は製造業、特に自動車やロボットなどメカトロニクスが強い。ここに導入することが外国企業にとってマネしにくい分野となる。
もう一つ、AIは用途ごとにカスタマイズしなければならない、究極の専用特化技術である。これも日本の得意なところだ。フアン氏はここに目を付け、日本が得意な分野にAIを活用することによって、生産性向上、再発見、予測、業務改善など様々なポジティブな成果を期待する。ソフトバンクグループCEOの孫正義氏は、Nvidiaと協力してAIグリッドを作ろうと提案した。ソフトバンクの持つ5G基地局のグリッドを使って、いつでもどこでもAIが使えるようにAIコンピュータを配備しようというものだ。

図2 フアン氏直筆のサインをいただいたエヌビディアの本 「津田さんへ、AIの未来へ、J. Huang」と書かれている
筆者はフアン氏が来日したので、先月発行した「エヌビディア~半導体の覇者が作り出す2040年の世界」の本をプレゼントしようと、記者会見後にフアン氏に接触した。彼は、「本なら自分で入手するから要らない、それよりサインしてあげるよ」と気軽に言い、重版した本にサインをいただいた(図1)。気を遣うとてもマメな方だと感じた。
エヌビディアに関する書籍は、実はこれが初めてであり、本場の米国ではまだ出版されていない(12月にようやく最初の本が出るようだ)。最近お会いした台湾のエンジニアたちも興味を示してくれた。韓国からも翻訳版の依頼がきているようだ。
エヌビディアの企業風土はユニークだ。組織はフラットで社長室はない。社員との壁を作りたくないからだ。各国、各地域にオフィスはあるが、世界中でフラットな組織を標榜する。中間管理職のいないフラットな構造にしたのは、フアン氏自身が複数の企業を経験してきた結果からだろう。企業内の派閥や内部争いがあると企業の力が削がれ、業務効率が悪くなる。しかも情報が正しく伝わらない。「ピラミッド構造にすると。1段上がるごとに情報は欠落する。トップに来るときには情報は半分以下だ」とフアン氏は語っている。
世界各地のオフィスではそれぞれがチームを組むが、レポート・ツー・CEOである。フアン氏は言う「このチームに上司(ボス)はいない。いるとすれば、プロジェクトが上司なんだ」。このため個人の責任は問われない。それだけではない。個人に裁量も与えられる。個人のやる気を最大限に引き出せる仕組みである。もちろん残業は多いが、「やらされ仕事」ではなく、「やる仕事」だからこそ、気のすむまで仕事に集中できる。
「エヌビディアの本」は、手前味噌かもしれないが、日本の経営層にぜひ読んでいただきたい本である。
知ってるようで知らないエヌビディアとは何者なのか
(2024年9月14日 11:17) エヌビディアという企業名を見ない日はないほど、今では知名度が向上したようだ。昨年半導体企業で初めて時価総額が1兆ドルを超え、今年の6月には一時的だったがアップルやマイクロソフトを抜き世界一になったときもあった。現在は3位に落ち着いているが、それでもグーグルよりも多い。

図1 PHP研究所が発行した「エヌビディア~半導体の覇者が作り出す2024年の世界」
その割には、いったいエヌビディアとは何者か。知名度は上がってきたが、その実態は知らない。こんな人たちが投資家を中心に増えている。新聞では半導体産業に関係する企業のようで、GPU(グラフィックスプロセッサ)を開発している半導体企業、という表現が多い。ただ、GPUという半導体製品を開発しているだけではない。GPUを使いこなしてAI(人工知能)を仕上げるためのソフトウエアや用途別のAIライブラリ、AIで推論するためのマイクロサービスなどAIに関するハードウエア(コンピュータボードやコンピュータ)とソフトウエア、そしてサービスまで提供するソリューションプロバイダーであり、プラットフォーマーともいえる。
How to makeからWhat to makeへ
そんな折、コンシューマ向けの書籍を出版しているPHP研究所からエヌビディアに関する本を出したいので、お話を聞きたいという連絡を受けた。なぜ私か?昨年、東洋経済の週刊誌でエヌビディアの記事を執筆したことがあり、指名されたようだ。私は、これまで半導体産業を40年以上追いかけてきた技術ジャーナリストだ。
半導体産業は30年以上前から、どうやって作るか(How to make)から、何を作るか(What to make)にテーマが移ってきた。このため設計が極めて大きな価値を持つ産業に変わってきた。それもシステム設計から論理設計、さらに回路設計、レイアウト設計、配置・配線設計など半導体設計に関するあらゆることを習得し、それらの設計工程を結ぶコンピュータを使った合成技術など学んでいかなければならなくなっていた。ところが、日本は相変わらず、製造中心に関心がある。
エヌビディアの経営トップのジェンスン・ファン氏は、半導体設計の基礎から応用までを網羅した指針となるべき「Introduction to VLSI Systems」というカリフォルニア工科大学(通称カルテック)のカーバー・ミード教授とゼロックスのコンピュータ科学者のリン・コンウェイ氏が共著で書いた本を紹介し、半導体設計を自分もこの本で勉強した、とカルテックの卒業生向けスピーチで述べている。
編集者の方とZoomでお話しながら、Nvidiaという会社についてお話ししたところ、書いてほしいということだった。これまで半導体業界やエレクトロニクス業界の人たち向けのB2Bの本や記事を書いてきた自分だが、コンシューマ向けの書籍は初めてだった。かつてエヌビディアの短い記事を執筆した東洋経済の編集者の方にも、なんで今エヌビディアについて知りたがっているのか、伺ってみると、やはり投資家が知りたがっているということだった。
わかりやすさを追求
実際にコンシューマ向けの本を書くことは実に難しい。実際に書いてみると言葉を選ぶのに時間がかかった。何度もダメ出しを食らい、わかりやすく受け入れてもらうような言葉に直して、エヌビディアの本を書いてみた。技術の内容を技術者ではない人向けに書くことは本当に難しい作業だった。かつて、東洋経済の方に、CPUコアベンダーのアーム社の製品やビジネスを説明するのに、何度も電話でやり取りしたことがあった。今回は、それ以上に難しかった。
エヌビディアは、GPU(グラフィックスプロセッサ)という半導体IC(集積回路)チップを開発した企業である。その特長は、写実的な絵を描くことだった。かつてのゲームはいかにもイラスト的な絵でしかなかったが、最近のゲーム機には実に映画のような写実的な絵が描けるようになっている。このような写実的な絵を描くための半導体ICがGPUである。GPUは単に画像処理ICと表現されることがあるが、画像処理だとイメージセンサなどで画像や映像を撮り込んだうえで何か処理をする場合の技術だという印象がある。GPUはそれと違い、画像そのもの、すなわち絵をコンピュータで描き出すためのチップなのだ。
なぜ、そのゲーム用の半導体ICが高性能なコンピュータやスーパーコンピュータに適しているのか、なぜ人間の神経ネットワーク(ニューラルネットワーク)をモデルにしたAI(人工知能)を実行するのに適しているのかを、説明した本や記事はほとんど見かけなかった。だから、この本「エヌビディア」ではこの説明を書きたかった。大変ありがたい機会だと思った。
日本から第2、第3のエヌビディアを
エヌビディアについて調べていくうちに、企業としても大変面白い組織だった。CEOであるジェンスン・ファン氏が講演などでプレゼンするときには必ず新しい革ジャンを着てくるが、そのことばかりが採り上げられ、彼の経営スタイルについてはほとんど日本では知られていなかった。経営者としても彼は極めて有能な人物である。
また、ジェンスン・フアン氏は、日本のこともよく知っているようで、創業仲間のクリス・マラコウスキー氏(現在も経営陣の一人)らとコンピュータグラフィックスを議論していた時に、日本のセガ、ソニー、任天堂のゲームメーカー3社の取り組みを大きな波と表現していた。また、カルテックでの卒業生へ講演した時にも日本の銀閣寺が登場した。彼らにぜひ手に職を得て欲しいというメッセージを伝える時に銀閣寺の苔の手入れをしている庭師の素晴らしさを引き合いに出し、職人(クラフト)になるように訴求した。
日本から第2、第3のエヌビディアを輩出させるためにどうすべきだろうか。浅田邦博東京大学教授らが始めたVDEC(VLSI Design and Education Center)を現在の池田誠教授が引き継ぎ、ここで半導体設計を教えているほか、京都大学の小野寺秀俊名誉教授やそこから輩出された優秀な先生方が半導体回路設計や論理設計を教えておられるが、まだ少ない。半導体設計技術をもっと多くの大学で教えなければ日本の未来は乏しい。
ラピダスのように製造に特化したファウンドリビジネスの創出もよいが、政府からの補助金が1兆円を軽く超え、コストがかかりすぎる。製造だけではユーザーも設計者も乏しくなる。幸い日本ではTSMCのみなとみらいにあるデザインセンターは最先端プロセス向けの半導体設計を日本人が行っているうえに、富士通とパナソニックのシステムLSI部門が合併したソシオネクストは、新しい半導体の設計を受注している設計者集団だ。台湾は政府(あえて使うが)が呼び掛けて、2000年頃、半導体設計を強化した。その結果、メディアテックやリアルテック、ノバテックなど世界のファブレストップテンに入る企業が続出した。
日本でも政府が音頭を取ってもっと半導体設計者を増やす算段をすべきであろう。米国の半導体の強さは、設計者の人口が日本に比べ圧倒的に多いことに関係する。文科省、経産省がもっと半導体設計者を増やすことに理解していただきたいと思うのは私だけだろうか。
早くも形成されたNvidia 包囲網
(2024年6月 7日 00:14) 5月下旬に発表されたNvidiaの2025年度第1四半期(2024年2月~4月)の業績はかつての2018年のメモリバブルを思い出す。当時Samsungは2018年第2四半期の営業利益率は55.6%という儲けすぎ(生産量をほとんど増やさず単価の値上げで売り上げが増えていたから)状態だったが、今のNvidiaもそれに近い状況が続いてきた。単価は高いものだと1個500万円もするらしい。2024年度第1四半期は調子が良いいつも通りの30%の営業利益率(GAAPベース)だったが、24年度第2四半期には50.3%、第3四半期に57.5%、第4四半期に61.6%、そして2025年度第1四半期には64.9%という儲けすぎ状態になった。

図1 Computex Taipei 2024でプレゼンしていたJensen Huang氏
営業利益率が50%を突破するという儲けすぎ状態はほぼバブルだといってもよい。Samsungは2018年第4四半期に営業利益率が50%を切ってからはどんどん下がりついには赤字になってしまった。Nvidiaはどうだろうか。
メモリはSamsung、SK hynix、Micronのトップ3社が92%以上のシェアを取る寡占化市場だが、AIでもNvidiaがGPUで8割を握ると言われるほどの独占的なプライヤーだ。だが、対抗プライヤーはスタートアップも含め徐々にスーパーコンピュータをはじめとするHPC市場にのし上がりつつある。ウェーハ規模の巨大なAIチップを特長とするCerebrasをはじめ、SambaNova、Tenstorrent、EsperantoなどスタートアップたちがNvidiaのチップよりも 桁違いに少ない消費電力を売りにAIチップに乗り込んできている。そしてうれしいことに東京に本社を置く日本のスタートアップEdgeCortixまでが低消費電力で高性能なAIチップをリリースしてきた(参考資料1)。
単なるAIチップメーカーだけではない。AIチップ同士をつなぐネットワークチップでは、Nvidia独自のNVLinkに対抗して、オープンアーキテクチャのネットワークチップを作ろうというコンソーシアムが出てきた。それもAMDやIntel、Broadcom、Google、Hewlett-Packard Enterprise、Cisico、Meta、Microsoftなどビッグネームの企業が集まってきた。彼らはEthernetベースのオープンな技術でAIチップ同士をつなごうといういう訳だ。UALink(Ultra Accelerator Link)と呼ばれるネットワーク技術でAIチップ同士を高速、低遅延でつなぐのだ。
NvidiaのNVLinkは、データセンター内のコンピュータ同士を並列接続して性能を上げられるようにするために開発されたネットワーク技術。ある程度InfiniBandをベースにしたもののようで、InfiniBandの得意なMellanoxを買収してネットワークチップをリリースしてきた。
一方のUALinkもデータセンター内のコンピュータ同士を接続して性能を拡張しようという技術。PCIe(PCI Express)のシリアルインターフェイスの拡張バスを使いながら、CXL(Compute Express Link)プロトコルを使って、CPU同士を結合させ接続する技術である。要は、独自技術のNvidiaのネットワーク技術が業界標準となるUALinkかという対立軸になる。
今年の第3四半期にはUALink 1.0の仕様が出てくるという。この仕様は最大1,024個のAIアクセラレータを接続できるらしい。
AIチップは並列動作の積和演算器とメモリの広いバンド幅を使ってデータの流れに従って演算の旅をするというアーキテクチャであるため、従来のフォンノイマン型から離れたアーキテクチャが有利であることが最近分かってきた。いわゆるデータフローコンピュータアーキテクチャである。少なくともこれまでのNvidiaのGPUは従来型のノイマン型コンピュータアーキテクチャである。1~2年はNvidiaの天下だろうが、その先はもはや混とんとしてくる。AIチップとインターコネクトネットワーク技術が拡張性のあるAI技術を握ることになる。ワクワクする時代に入ることになる。
参考資料
1.
津田建二、「日本生まれで多様なファブレス半導体EdgeCortixが本格的なAIチップを発売」、News & Chips ,
(2024/6/1)
日本生まれで多様なファブレス半導体EdgeCortixが本格的なAIチップを発売
(2024年6月 1日 22:48) 日本生まれのスタートアップが本格的なAI専用チップの製品化にようやくこぎつけた。このEdgeCortix(エッジコーテックス)社の社長兼CEOとなるサキャシンガ・ダスグプタ(Sakyasingha Dasgupta)氏は、これまでドイツのマックスプランク研究所や日本の理化学研究所でAIコンピューティングの開発に携わり、2019年に東京で起業した。北尾吉孝氏率いるSBI Investmentや、ルネサスエレクトロニクスなどの出資を受け、ファブレス半導体企業としてエッジAIをビジネスのコアと置いた。

図1 EdgeCortixのCEOであるSakya Dasgupta氏
チップの製品化に先立ち、ソフトウエアベースのエッジAIコンピューティング手法を採り、国内でMERAというコンパイラとソフトウエアフレームワークを開発するとともに、AIチップアーキテクチャの中心となるDNA(Dynamic Neural Accelerator)技術を開発してきた。DNAは動作中に再構成可能なプロセッサアーキテクチャ。ノイマン型の従来のコンピュータの次世代と言われるデータフローコンピュータアーキテクチャを採用する。この二つの技術を生かしたのが今回リリースした「SAKURA-II」というAIアクセラレータチップだ。開発当初は、FPGAでプロセッサ回路を組み、動作を確認し、新アーキテクチャの実用性に自信を持ち、今回の「SAKURA-II」新プロセッサ(図2)となった。

図2 今回開発したSAKURA-IIチップ搭載ボード
製品の特長は、60TOPS(Tera
Operations per Second)という性能を持ちながら、消費電力がわずか8Wと極めて低いことだ。MicrosoftがAI機能であるCopilot+PCの定義の一つとして40TOPS以上の性能であることを掲げているが、SAKURA-IIはこの性能を十分超えている。しかも消費電力は一桁ワットと、パソコン用のエッジAIとしても極めて小さい。
日本で生まれた、このスタートアップ企業は日本ではエッジAIのニーズがあり、しかもSakyaさん自身も日本を良く知っており、なじみがある。今はむしろ米中対立が激しくなっており、比較的中立的な日本は仕事しやすい環境にあると述べている。とはいえ、さらに広い市場を目指すため、米国とシンガポール、インドにもオフィスを置き、日本には川崎市の武蔵小杉にエンジニアリングセンターを置いている。ミッションとして、クラウドレベルに近い性能をエッジで提供し、エネルギー効率と処理速度を桁違いに向上させ、顧客の運用コストを大幅に削減すること、としている。だから、低コストでしかも低消費電力の生成AIチップを提供することを目的として掲げた。
もともと生成AIは英語ベースのLLMで、特にチャットGPTは少し古い情報を学習させていた。しかし、日本語ベースの情報を学習させる開発が国内で行われており、消費電力の少ないエッジ端末で日本語ベースでの生成AIを活用できると、かなり日本企業にとっても使い道は多くなりそうだ。
ちなみに、EdgeCortixは、5月22日~24日、東京ビッグサイトで開催された第8回AI・人工知能EXPO(春)で製品のデモをいくつか行っていた。2台のIR(赤外線)カメラで人物とその距離を測定した二つの映像を示したり、16のシーンを1チップだけで表示したり、超解像技術に使ったりするようなデモを示していた。このチップは放熱フィンはいらない上、エッジ端末のどこにでも組み込める大きさのボードやカードに組み込まれている。
今回のチップはTSMCの12nmプロセスで作られたものだが、今後はJASMの熊本を利用しやすくなる、とSakyaさんは期待する。2nmプロセスはコストが極めて高いため、エッジAIの目的には当分必要ないかもしれないが、ラピダスだけではなく、台湾のPSMCも日本で生産するようになるとファブレス企業の受け皿は増えるようになる。
また、日本人だけのスタートアップとは違い、さまざまな国からの人材がこの企業には集まり、ワイワイガヤガヤと議論している姿は、まるでシリコンバレーの企業を想起する。日本でもこんな面白いスタートアップのファブレス半導体が出来たことは日本の半導体産業のこれからの未来は明るくなるような予感がする。日本におけるファブレス半導体の起業に期待は大きい。
米政府、TSMCアリゾナ工場に66億ドルの補助金をやっと提供した理由
(2024年4月 9日 13:45) 米国商務省は、CHIPS+科学法案に基づき、TSMCのアリゾナ3工場に66億ドルの補助金を提供することでTSMCと合意に達した。これまでズルズルとなかなか米政府は補助金を出してこなかったが、これがTSMCに対する初めての補助金となる。TSMCはすでに着工しているアリゾナ州工場に二つの工場を建設しているが、3番目の工場も建設することになった。なぜここまで遅れたか。

第2工場は2nmプロセスを主体とするが、第3工場は2nm以降のプロセスの生産工場となる。すなわち最先端の工場をアリゾナに作ることになる。これまでは5nmプロセスの工場だとしていた。TSMCはアリゾナの3工場に650億ドル以上の投資を計画しており、この第3工場を発表したことも今回が初めてである。これまでは2工場で、しかも最先端ではなかったことも、これまでの計画とは大きく違う。
これまでTSMCへの補助に対して、IntelのPat Gelsinger氏は、補助金を出すなら米国企業に限るべしとの意見を述べていた。そういった声に対して、TSMCに第3工場の建設を約束させ、さらに2nm以降という最先端工場にして補助金を出すことになったといえる。第3工場は今後10年以内に建設されることをTSMCが約束している。
米国政府は、「TSMCのアリゾナ工場は、米国内で信頼のある工場でチップを製造することによって、米国経済と国家の完全を強めるための重要なステップになる」と一応、述べている。半導体チップは今後の経済の礎となり、AIブームをはじめとするコンシューマエレクトロニクスや車載機器、IoT(Internet of Things)、HPC(スーパーコンピュータをはじめとする高性能コンピューティング)など急成長している産業を強力に後押しする、としている。
この3つの工場によってアリゾナ州は先端技術のクラスタを構築することになり、約6000名の雇用を直接生み出し、工場建設に延べ2万人を投入することになる。今後の10年間で関節も含め数万人を雇用し、米国に最先端のプロセス技術をもたらすという。
Made in Americaが重要
バイデン大統領は次のように語っている;「爪ほどの大きさしかない半導体は米国が発明したのにもかかわらず、かつては世界の40%を製造していたが、今では10%に下がってしまった。しかも先端技術を持っていない。今や米国は、重要な経済と国家安全が脆弱な状況に晒されている。だから、CHIPs+科学法案のおかげで半導体製造と雇用を米国に取り戻すことができるようになる」。TSMCであろうと、米国製のチップが米国の先端技術となり、米国工場を強く支持するとしている。
米国では米国製(Made in America)であることがとても重要で、ボストン在住の友人はかつて「フォードは米国車じゃない。メキシコで作っているのだから。トヨタは米国製だけどね」と語っていた。企業の本社の国籍ではなく、どこの工場で作られたことなのかを問題にしているのだ。
当初のTSMCのアリゾナ工場では5nmプロセスノードの工場だとしていたが、2023年12月には4nm工場と修正し、今回は2nm工場としたことで、先端技術を米国で生産することが可能になり、バイデン政権が納得したのであろう。というのは、レモンド商務省長官は次のように語っているからだ;「バイデン大統領の重要な目標は、世界最先端の半導体プロセス工場を米国にもたらすことだった。TSMCの工場を(第3工場まで)増やしたことで、この目標を達成できると見た。TSMCが投資を増やし先端の第3工場を約束してくれたおかげでサプライチェーンが強化されるようになる」。
TSMC会長のMark Liu氏も「CHIPs+科学法案のおかげで、TSMCは米国に最先端技術の工場を作るチャンスに結びついた。米国工場があれば当社の米国大手顧客企業をもっとサポートできる」と語っている。TSMCの米国顧客には、AppleやNvidia、Qualcomm、AMDなど世界的なファブレス半導体企業が大勢いる。
ただし、TSMCと商務省がサインしたのは、拘束力のない暫定的な規約覚書(non-binding preliminary memorandum of terms:PMT)であるが、このPMTでは、TSMCの半導体工場作業者と建設従事者を呼び込むための資金として5000万ドル(75億円)も提案している。アリゾナ工場へのエンジニアの採用がなかなか進んでおらず、人の採用も問題視されていた。
エルピーダを再興させた坂本幸雄氏、ご逝去ニュースの謎
(2024年2月27日 15:56)なぜだろうか、不思議でならない。いまだに日本の半導体にとってこれほど重要な人物の一人であった坂本幸雄氏が逝去されたというニュースをマスメディアが全く採り上げなかったことである。
坂本さんは2月14日に心臓発作で帰らぬ人となったようで、家族だけで葬儀を行ったという。エルピーダメモリを再興させた坂本さんご逝去のニュースを、台湾メディアは一斉に報じていたのにもかかわらず、26日まで日本のメディアはどこもこのニュースを扱わなかった。27日にようやく日経が採り上げた。

図 在りし日の坂本幸雄さん エルピーダメモリの社長時代 出典:筆者撮影
台湾のメディアは、坂本さんご逝去のニュースをほとんどが採り上げていたことと対照的だ。台湾の有力メディアであるDigiTimesは坂本さんを「最後の日本のメモリ指導者」、別のメディアは「日本半導体の父」や「半導体産業の救世主」と称えた。
坂本さんは、日本体育大学を出て、日本テキサスインスツルメンツに入社した。ここで倉庫番から始め、最終的に副社長になられた。しかし、日本TIは社長を外から採用した。坂本さんは、日本TIを出てメモリやファウンドリなどの企業を経て、2002年、日立製作所とNEC、三菱電機との合弁会社エルピーダメモリの社長に迎えられた。
当時のエルピーダは、大手DRAM部門同士が一緒になり、大企業病にかかっていた。坂本さんは「毎年400億円の赤字を連続3年垂れ流しているのに、出張にはファーストクラス、日常はゴルフの話ばかりの役員が多かった。彼らには親会社に帰ってもらった」と語っており、日立やNECなどからの独立を図り始めた。
DRAMのような大量生産品は、巨大な設備投資を行い、ウェーハの大口径化と配線線幅の最小化、すなわち微細化を行いコストダウンしていくビジネスである。日立もNECも子会社したのにもかかわらず、エルピーダ設立後はもう資金を提供しないから自分で利益を上げよ、と言っていた。しかし投資せずに利益を上げることはできない。そこで、坂本さんは、資金調達するため欧米を中心に回り、Intel Capitalをはじめファンドから1800億円の資金を集めた。これを元手にエルピーダに投資、DRAM量産で遅れていた設備を一新させ低コストで生産する仕組みを構築した。翌年早くも黒字化を達成した。そして、2011年には世界第3位のDRAMメーカーになった。
歴史を簡単に書いたが、その中身には坂本流が満載されている。一つは社員のストックオプション。米国企業のストックオプションは役員レベルにしか与えられないが、元TIにいた坂本さんは社員を優先して与えた。もう一つは業績と連動したボーナス。エルピーダは米国企業のように四半期ベースで決算報告を行うが(現在は日本企業の多くが四半期ベースの決算を行う)、営業利益率が15%を超えたら社員に0.75ヵ月分のボーナスを与えた。20%を超えたら役員にもボーナスを与えた。社員のやる気は高まった。
しかし、リーマンショックによる影響はじわじわ製造業を締め付けてきた。金融業界はエルピーダに対して全く資金を貸してくれなくなった。キャッシュフローが尽きたところで会社更生法を適用したが、工場は運営し続けた。坂本さんはエルピーダ広島工場に管財人として残り、売却先を求めて奔走した。Micron Technologyに売却することで従業員の雇用を守ることができた。
その後、中国において活動し始めた中、2月14日に心臓発作を起こし帰らぬ人となった。台湾メディアがいうように坂本さんはエルピーダを再興させた人間であり、リーマンショックがなかったら、、、と今でも思う。
合掌
生成AIでも、かつてのニッポン第5世代コンピュータの失敗を繰り返すな
(2024年2月 4日 16:02) 生成AIのビジネス化に向かうNvidiaとIBMの取り組みを最近聞いた。2社に共通するのは、しっかりとしたビジネスを指向する戦略である。Nvidiaはもともとニューラルネットワークモデルに基づいたAI(ML:機械学習)の演算に、ゲーム機向けのグラフィックプロセッサ(GPU)に集積された大量の積和演算器を使うことから、GPUがAI演算に向いていることをいち早く察知した。AIのさまざまなライブラリを採り入れたり、AI用のモデルを提供したりAIおよび数値演算専用のHPC向けのGPUにフォーカスしてきた。
IBMは、機械学習を自社のコンピュータ「ワトソン」に学習させ、TVのクイズ番組Jeopardy!で、生身のクイズ王に勝利したというエピソードを持つ。自然言語処理技術の開発からAI技術を発展させ、AI/MLをビジネスのツールとして活用してきた。
22年秋にOpenAI社が生成AIを公開し、そのうちの一つチャットGPTはテキストで尋ねると、テキストで答えてくれるだけではなく、新しい文書(小説や論文、要約など)を生み出すことで急速に広がってきたチャットGPTは政治から経済・文学・物理・化学、電子回路など何でも答えてくれるように膨大な学習をさせたAIシステムであり、その学習に使われたNvidiaのGPUの数は数千個とチャットGPTが答えている。生成AIに新規参入したAI企業からNvidiaのGPUは奪い合いになるほどの需要があった。
日本でも日本語ベースの生成AIを開発する企業が登場、スーパーコンピュータ「富岳」を使って開発している。さらに政府からも生成AI開発企業に補助金を用意するといった対応が進んでいる。OpenAI社よりももっとパラメータの多い巨大なAIソフトウエアを開発する方向に向かっているようだ。OpenAIはGPT-3から最も巨大なGPT-4へと進み、日本政府もその後を追いかけているように見える。
大きいことは良いことではない
しかし待てよ。NvidiaとIBMの生成AIに対する戦略は、OpenAIのチャットGPTのようなひたすら巨大なソフトを開発する方向ではないのだ。共に創薬をはじめとする医療やヘルスケアなどに特化する生成AIを開発している。なんにでも使える巨大なソフトより、狙った応用に特化したビジネスを優先している。

図1 David Niewolny氏、NvidiaのDirector of Business Development for
Healthcare/Medical
Nvidiaの戦略を先週、日本にやってきたNvidiaのヘルスケア事業開発担当ディレクターのDavid Niewolny氏(図1)に確認してみたところ、生成AIのビジネスを優先してヘルスケア事業に特化したAIおよびアクセラレータのプラットフォーム「Nvidia Clara」を開発したのはその通りだったと答えた。Nvidia
Claraでは、5つの専用のコンピュータプラットフォームがある。遺伝子解析にParabricks、自然言語処理にNeMo、創薬開発にBioNemo、医療向けイメージングにMONAI、医療デバイスにHoloscanを持っている。
2023年には、創薬開発を促進するためタンパク質の特性を設計し予測する生成AIを開発するため、Amgen社がNvidia BioNeMoとDGXクラウドを採用したという。また、新型コロナの時に人工呼吸器で一躍有名になったアイルランドのMedtronic社はNvidia Holoscanを採用、同社のリアルタイム内視鏡デバイなどの医療機器向けAIプラットフォームを構築する。さらにNvidiaは、バイオテクノロジー大手のGenentech社とも戦略的共同開発提携を結び、生成AIのモデルとアルゴリズムを開発、次世代AIプラットフォームに載せていく。
かつて経済産業省は、「第5世代コンピュータ」プロジェクトを始めたものの、先端技術の開発しか目を向けなかったために、コンピュータ業界の大きなトレンド「ダウンサイジング」の波に乗り遅れ、日本のコンピュータ産業は結局パソコン技術で世界競争から脱落した。その結果、コンピュータ用の半導体でも、メインフレーム向けの高コストDRAMしか作れず、低コストのDRAMを作れなかったため、MicronやSamsungに大敗した。
ラピダスに対しても2nmという先端プロセスばかりに目が行っており、大きなビジネスを示す28nm、16nmプロセスを忘れている。生成AIも同様で、巨大な生成AIを作るためのGPT-4や5などの開発を指向し続けている。実ビジネスは、1750億パラメータという巨大なGPT-3ではなく、100億、数十億パラメータの絞られた分野の生成AIに指向している。これがNvidiaとIBMの戦略だ。日本政府経産省がまたしても道を間違えないようにウォッチしていく必要がありそうだ。
CES 2024に見るテクノロジー・半導体の広がり; 化粧品ビジネスまで拡大
(2024年2月 3日 08:36) 1月8日から始まったCES 2024では、最初の基調講演が化粧品最大手のL'Oreal(ロレアル)と小売流通最大手のWalmart(ウォルマート)の経営トップによるものだった。小売りでの電子技術の導入はRFタグやPOS端末、防犯防止監視カメラ、IoTセンサなどの利用など実績は古い。こういった応用全てを動かすテクノロジーは半導体である。しかし、化粧品ビジネスでITや半導体エレクトロニクスを使うようになったとは夢にも思わなかった。

図1 L'Oreal社CEOのNicolas Hieronimus氏の基調講演 出典:CES 2024 での基調講演ビデオから
L'Oreal経営トップのNicolas Hieronimus CEOの話(図1)はハプニングもあり面白かった。化粧品ビジネスのテクノロジーは、肌への副作用を研究するためのテクノロジーが古くからあったが、近年のテクノロジーは化学的なテクノロジーではなく、ITや半導体エレクトロニクスを駆使したテクノロジーに変わってきていると語る。そして、生成AIに尋ねるというデモを見せた。パリからラスベガスにやってきて長いフライトで疲れた肌にはどのような処置をすべきかを生成AIに聞き、自分の写真を送ってみたところ、生成AIがあなたの年齢は?と尋ねてきたため、そこで質問を止めてしまった、というハプニングが起きた。
CEOは、新しい美へのテクノロジー(Beauty Technology)の事例をいくつか示した。まず、髪の毛を染めるカラーソニックデバイスを紹介した。これは、ブラシの付いたデバイスで髪の毛をなぞるだけでプロ並みに染められるというビデオを見せた。技術の説明はなかったが、染めるための2種類の薬剤をブラシの先に送り超音波で髪となじませるようだった。超音波で二つの物質をくっつけるという技術は古くからあり、半導体技術では超音波ボンディングがそれにあたる。
もう一つの例は、熱を発しないヘアドライヤーだ。これも詳細は述べていないが、示したビデオから、IR(赤外線)パルスを照射して髪を瞬時に温め乾燥させるようだ。キューティクルが暴れることなくきれいな状態を保ったままだった。サーモグラフィで従来のヒーター式のドライヤーと比べた結果、髪の毛に当たる風の温度は20度を示していた。デモを紹介したビデオには、半導体チップが映っていた。CEOは、半導体技術まで言及しなかったが、これらのテクノロジーを実現するためには超音波振動子を動作・制御させるためのICは欠かせない。またIR駆動回路にも半導体ICは必須だ。
彼は最後に、美容技術の将来は、パーソナル医療と同様、化粧品もパーソナル化していくだろうと述べた。一人ずつDNA解析によって個人に合った化粧品を提供するのである。
AIビジネスは始まったばかり
半導体企業からはIntelのPat Gelsinger CEOが基調講演に登場、CNBCの記者との対談形式で話をした。IntelはAI Everywhere戦略を掲げている。Gelsinger CEOは、AIはまだ始まったばかりであり、かつてのWi-Fi勃興期と似ていると述べた。その20年後にはWi-Fi通信が当たり前になったように、AIも20年後には当たり前になると述べている。
スマートフォンのモデム(変復調回路)やモバイルプロセッサのトップメーカーQualcommのChristiano Amon CEOも、生成AIは野球の9回のイニングで言えば何回なの?と質問され、まだ1回か2回だ、と答えた。QualcommのDNAは消費電力を下げるテクノロジーだからこそ、高性能のデータセンターと相補的に役割分担しながらAIは進んでいくと答えている。
半導体産業はこれからもまだまだ成長していく、という認識ではIntelもQualcommも同じである。残念ながら日本だけが長い間、半導体を斜陽産業という間違った認識を持ってきたため、世界から大きく取り残される結果になっている。つまり、何度も見せた、世界は成長しているが日本だけが成長していないというこの30年間に渡る事実(参考資料1)をしっかりと見据え、この遅れをこれから取り返していかなければならない。
ちなみに昨年9月に予想した11月には確実に前年比プラスになる、と参考資料1で予想したが、実際には9月にほんの僅か0.3%程度プラスになり、10月に同6%増、11月には2桁成長の同12%増となっている。半導体は回復基調に推移している。
参考資料
1. 「半導体不況からの脱出、11月には確実に前年比プラスになる!」、News & Chips,
(2023/09/28)
女子高生にとって理系・工学部は狙い目、理系・工学系女子に期待
(2024年1月31日 21:13)大学入学試験がほぼ終わり新学期の準備に入る頃になったが、これからは女子高校生にとって理系大学は狙い目かもしれない。かつては、女性の理系は、生物系か建築系などに少し在籍していたが、工学系にはほとんどいなかった。最近になり、女性エンジニアが少しずつ増えつつある。半導体の世界でも古くから女性エンジニアはいることはいたが、極めて少なかった。今や男性だけではなく、女性の半導体エンジニアも強く求められるようになってきた。
ITも半導体もこの先、50年は発展できる産業である。ここに人材がいないことはこの先も日本が成長できないことになる。となれば円安はますます進み、輸入による物価高が国民を襲う。このような危機的状況の中では、男だけがエンジニアや研究者を続ける意味がない。女性もエンジニアや研究者として力を発揮してほしい。そのためには女性は理系に向かないといった偏見を打破し、女性も男性と対等な立場で仕事するという環境作りが重要になる。経営者の理解も重要だ。

図1 東京工業大学 大岡山キャンパス 出典:東京工業大学
東京工業大学が2024年4月入学から女子枠を広げる。現在学士課程全体で女子学生の割合は10~13%程度しかない。これを20%に引き上げようという試みである。だからといって女性だけ試験の点数を甘くするという訳ではない。女子枠において総合型の学校推薦選抜を設け、高等学校が推薦し、さらに面接で最終的に合否を決めるというもの。面接で落ちたとしても、一般入試で合格すればよいというリターンマッチもある。
こういった試みは東工大だけではない。北から、北見工業大学や山梨大学、富山大学、金沢大学、名古屋大学、名古屋工業大学、島根大学、熊本大学、大分大学、宮崎大学、長崎大学、琉球大学などがあり、奈良女子大学やお茶の水女子大学には工学部もある。女性のエンジニアが活躍するようになれば、日本の産業は活気づく。
産業界も歓迎している。半導体製造装置企業国内トップで世界でも4位である東京エレクトロンの河合利樹社長は、セミコンジャパン2023の講演の中で人材育成に触れ、「ジェンダー問題は解決すべき課題の一つであり、女子学生の枠を広げるという動きを、東京エレクトロンは歓迎するとともに、積極的にサポートしていく」と述べている。事実、東京エレクトロンには女性社員やエンジニアが多い。
かつて米国シリコンバレーのある調査会社が実施したハイテク企業経営者へのアンケートについて取材した。その結果、シリコンバレーで働く人の男女比率は49対51で女性がわずかながら多かった。ハイテク業界の競争が最も厳しいシリコンバレーでは、ジェンダー問題の解決なしで企業は勝ち抜けないことを示している。
日本でも半導体産業の成長性を信じる人たちがようやく増えてきた。2020年代に入り、経済産業省が世界トップクラスの半導体メーカーである台湾のTSMC社を日本に誘致し、新たにラピダス社設立に動きだした。巨大な投資を支援することが決まったが、最大の問題は人材。半導体産業を理解できる人材がとても少なくなってしまった。これでは、せっかく成長性のある半導体産業を再認識しても産業が育たなくなる。
今からでも遅くない。半導体を理解できる人材を育成することは日本の未来につながる。デジタルトランスフォーメーション(DX)もカーボンニュートラルのグリーントランスフォーメーション(GX)も日本の未来に重要な技術であるが、その中核技術は、ITであり半導体である。ITはサービス産業であり、そのテクノロジーこそが半導体なのだ。半導体は産業のコメから産業の頭脳に変わった。頭脳なしで未来はない。その一例として、チャットGPTを開発した米OpenAI社のアルトマンCEOが半導体工場を探しているという最新ニュースはそのことを示している。
ラピダス工場進出に沸く北海道
(2023年12月 7日 21:52) 最先端の半導体プロセス工場を設置することをラピダス社が発表して以来、北海道は半導体工場の誘致に沸いている。北海道を代表する新聞の北海道新聞は、「2ナノへの挑戦」「迎えた転機」「半導体新時代」といった連載・特集を2023年に入り、続けてきた。また、最新ニュースでも半導体関連のニュースが多い。
北海道はこれまで大きな産業がなく、ラピダスに期待する声は強い。半導体工場が一つあれば(図1)、半導体工場で使うきれいな水、一般的なガス(窒素ガスや酸素ガスなど)や特殊ガス(アルシンやフォスフィンなど)、化学薬品、有機溶剤などサプライチェーンが必要になる。つまりさまざまな企業がその周りに出来て、一つの半導体製造産業が成り立っている。規模にもよるが、保守要員も必要となる。半導体工場の周辺設備は、台湾の新竹、ドイツのドレスデンなどが有名で、かつては熊本もその一つに数え挙げられていた。

図1 新千歳空港のすぐそばで建設が始まっているラピダスの現場 筆者撮影
最新プロセス開発研究を行っているベルギーの半導体研究所imecが北海道にやってくるという話もあり、期待が大きい。11月9日に東京で、ベルギーの半導体研究所imecの技術シンポジウムであるITF(Imec
Technology Forum)が開かれ、CEOのLuc van den Hove氏に尋ねてみると、「北海道に拠点を開設する計画はあるが、まだ決定したわけではない。しかも日本進出となるとほかの企業にもアプローチしたいし」と答えた。そこで、「だとすると東京に本部を作ることになりますね」、と尋ねると頷いた。恐らく東京に支社か現地法人を作り、北海道に連絡事務所を置くのではないだろうか。
また、ソフトバンクは北海道苫小牧市の東地区にデータセンターを建設する計画を発表している。苫小牧から千歳、さらに石狩(さくらインターネットがデータセンターを所有)地区にかけて、「北海道バレー」にしようという構想をラピダス社長の小池淳義氏がぶち上げている。北海道側はラピダスがもたらす波及効果の大きさに期待は大きい。
現実には、さまざまな企業が進出したり物資を提供したり、協力なしでは実現できない。「手探りのままスタートしている状態」だと言えそうだ。例えば、半導体工場に欠かせない水は当初、千歳川の支流などから持ってくると伝えられていたが、それだけでは間に合いそうもなく、苫小牧地区工業用水道浄水場から中継ポンプ場を通して配水管を設けることに決定した。
ラピダスを支援するための組織として、北海道新産業創造機構(ANIC)が設立され、半導体関連産業の集積や道内企業との取引強化など北海道経済の新たな発展に貢献することを目的としている。力の入れようはすさまじく大きい。
国頼みの経済からの脱却
ここまで期待するのは、これまで北海道には大きな産業がなかったからだ。かつて夕張炭鉱があり、それを利用して室蘭に製鉄所があった。しかしそういった産業の没落と同時に新産業を生み出すための力が及ばず、沖縄と並んで、北海道・沖縄を開発する組織が国にはあり、援助金が配布されていた。
今回、ラピダスが北海道に来るということで、これまでの国頼みの経済から自立した産業を持つ経済へ移行する千載一遇のチャンスなのだ。これまでは点としての工場はいくつかあった。旧日立北海セミコンダクターを買収したミネベアミツミや、京都セミコンダクター、アムコー・テクノロジー・ジャパン、セイコーエプソンなどはある(図2)。しかし点在していただけだった。
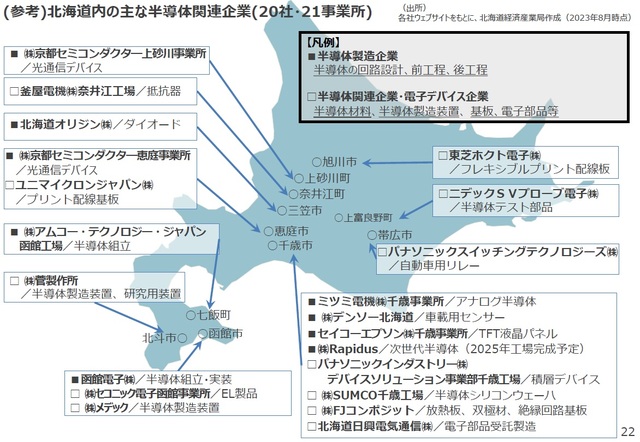
ラピダスのような規模の大きな半導体工場がやって来ると、半導体製造材料や装置の工場や保守企業も欠かせない。北海道庁をトップにさまざまな組織がラピダスを支援する体制作りに奔走している状況だ。早くも「北海道バレー」といった構想も期待されている。
この構想が決して的外れではないのは、半導体をけん引する産業が電機からITへとシフトしているからだ。ITは本質的にサービス産業であり、そのテクノロジーは何かといえば、コンピュータと通信と半導体である。この三つの内の一つが欠けてもITは成り立たない。幸い札幌にはかつてゲームソフト開発が盛んだった時期があった。コンピュータのハードウエアは今や半導体、ソフトウエアはかつての「札幌バレー」が担える可能性がある。
ただ、最大の問題は、半導体人材が足りないことだ。北海道には北海道大学をはじめ理科系の大学・高等専門工業高校(高専)が11校しかない(表1)。全体でも5100名程度の学生しかいない。さらに問題は、半導体を学ぶカリキュラムが乏しいことだ。
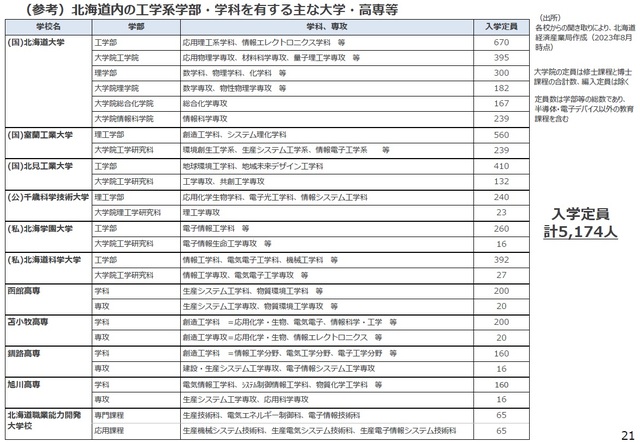
表1 北海道内の理工系大学・高専と学生数 出典:北海道経済産業局
半導体の世界は、実は奥深い。半導体物性を教える先生はたくさんいるが、半導体トランジスタを教える先生が少なく、しかも半導体回路(IC)となるともっと少ない。そして半導体IC設計となると全国でさえも指で数えられるほどしかいない。半導体ICを製造するプロセス技術では、50~60歳のベテランがまだ生き残っている。彼らに教えてもらえばよい。そして出来た半導体ウェーハをカットしてチップに加工した後、ワイヤーボンディングなどの配線工程と封止して外界から守るパッケージング技術も必要だ。テストも重要で、狙った性能・機能が得られるかどうかをテストするのであるが、半導体ICそのものがコンピュータとなっているため、テストプログラムを書いて狙い通りの機能を実現できるかをチェックするためのソフトウエアとハードウエアを理解した技術者も求められる。
それだけではない。半導体ICを使うシステムの知識がなければ、半導体ICを売ることができない。しかも核心を突くシステムの知識は、米国のシリコンバレーから発信されることが多い。米国と交渉できるシステム技術と半導体知識を持つ人間が欠かせない。英会話能力の問題ではない。中身の知識が絶対的に必要なのだ。
北海道科学大学で工学部長兼機械工学科学科長の見山克己教授はため息交じりに次のように語っている。「半導体教育の中で、例えば半導体物性や半導体物理の専門家はいても、産業、技術など全体がわかる人が極めて少ない。特に半導体の設計については人材が薄い。これまで北海道が主催するさまざまな懇談会のレポートを見てもわかりますが、みんなの知識は断片的ですね」。
半導体の世界は変化が激しいだけではない。例えば製造工程で抑えるべきプロセスパラメータが実に多く、それらは相関あったり、なかったりで、ビッグデータ解析からAI/ML(機械学習)解析まで5~6年前から採り入れられている。つまり新しい知識の吸収も極めて速くなければならない。最新技術にも目を配り、いち早く自分のものにしなければ世界とは競争できない。北海道の期待は大きいが、北海道自身も早い変化にしっかり対応できるように変わらなければならないだろう。