

3nm、5nm、7nmという微細なプロセスを使った半導体は、先端半導体あるいは先端プロセスなどと呼ばれることが多いが、実はそのような3nm、5nm、7nmなどという寸法は半導体チップ上のどこにも存在しない。これは14nm/16nmプロセスより先のプロセスで実際の寸法と、x nmプロセスという言葉とが大きくかけ離れてしまってきたことに起因する。
5nmや7nmだから先端で、14/16nmプロセスは成熟、と表現するのはお門違い。どちらも最小寸法は12~14nm程度とほとんど変わらないからだ。そもそも波長13.5nmのEUVリソグラフィでそれ以下の寸法を加工できるのか。物理学では波長よりも小さな寸法は光が入っていかない。このため光の縦波あるいは横波だけを通すようなパターンを加工してきたのが現実だ。光源の強度分布を変えたり、横長あるいは縦長のパターンだけでトランジスタを構成したり、光の屈折率を利用するため水に浸して露光する液浸技術を使ったり、ダブルパターニングのようにパターンを寸法の半分だけズラして露光したりして物理学上の壁を突破しようとしてきた。
しかし、EUVの波長13.5nmまで来るとさすがにこれまでのような工夫は難しくなってきた。このため、3nmプロセスといっても実際の寸法は12nm程度にとどまっている。よく言われていた逸話では、Intelの10nmプロセスの性能指数や集積度は、TSMCの7nmプロセスに近いといわれてきた。
そしてTSMCのようなロジックプロセッサを製造しているメーカーとは違い、Samsungやキオクシアのようなメモリメーカーは、同様な寸法を比較的正直に伝えてきた。比較的と言ったのは実寸法に近い寸法を使ってきたからだ。ただし、実際の寸法は告げずに20nm以下のプロセスで、19nmプロセスを1x nm、17~18nmプロセスを1y nm、16~15nmプロセスを1z nmプロセスなどと言ってきた。つまり1~2nmごとに細かく刻んできたのである。
実際の寸法では技術の進化を表せない
ではなぜ、実際の寸法とは異なるサイズを掲げるのか。メモリもロジックも技術的な進展が少ないと思われるのを避けるためだ。メモリでは、15nmより先の14~13nmを1α
nm、13~12nmを1β
nmと呼んでいた。ところが、このほどSamsungが発表した32GビットDDR5 DRAMでは実寸法の12nmと述べている。
ロジックはまだ、3nm、そして2nmプロセスと述べている。しかし、現在のロジックプロセスでは配線幅/配線間隔のピッチはEUVリソグラフィを使って20~30nmが最も微細といわれている。この先EUVのダブルパターニング技術が使われるようになるが、それでも最小ピッチは15~20nmだといわれている。
ではどうやって5nmや3nmと呼ばれるプロセスを実現するのか。実はもはや寸法の微細化はほぼ止まっているため、配線幅/配線間隔の寸法(あるいはピッチ)ではなく、単位面積あたりに集積できるトランジスタ数で、表現しているのだ。これを台湾における半導体設計の論客であるNicky Lu氏は面積スケーリングと呼び、これまでの線形(リニア)スケーリングからエリアスケーリングにシフトした、と表現する。例えば、Intelの10nmプロセスでは1平方ミリメートル当たりのトランジスタ数は最大1億個だが、TSMCの7nmプロセスでは同9120万トランジスタで、ほぼ等しいプロセスノードだといわれていた。
3次元構造を駆使するエリアスケーリング
この面積スケーリングとはどのような技術を指すのか。一つは、MOSトランジスタそのもので、プレーナMOSトランジスタからFinFET構造(図1)に変わり、3次元の縦方向にも電流が流れるようにしている。縦方向の壁に沿って電流が流れることで1個のトランジスタの面積は、プレーナ型よりも小さくできる。また配線では、多層配線が使われているが、スルーホールやコンタクトホールなど配線同士が交差する穴を、絶縁膜を介して配線上に設けるような3次元構造に変えた。また配線の幅や配線間隔を詰めない代わりに、できるだけ3次元構造にして配線の端(端子)から端(端子)までの距離を短くし面積当たりの配線密度を上げた。
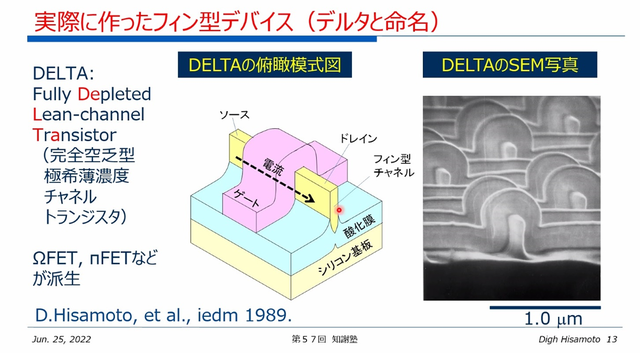
図1 FinFETの発明者は日立製作所の久本大氏で、彼は当初DELTAデバイスと呼んでいた 出典:久本大氏からお借りした
エリアスケーリングではこれまでの比例縮小則が使えないため、前世代のスタンダードセルは3次元構造に全て作り直しになる。このためコストは極めて高くなる。実は、TSMCのこういった設計の作り直し作業は、横浜みなとみらいにあるTSMCデザインセンターで行われている。このため日本人設計者は台湾と密に連絡を取りながら7nmや5nm、3nmなどのプロセスノードの設計を行っている。日本の設計エンジニアのレベルは高く、TSMCを支えているといっても過言ではない。
ロジックでこのように3次元化して集積度を上げたことで、7nm相当、5nm相当の集積度を得ることができ、性能を上げ消費電力を下げることができた。TSMCとIntel、Samsungはそれぞれが勝手に自分らのプロセスを7nmプロセス、10nmプロセスと呼んできた。ロジックでエリアスケーリングを使っているのはこの3社しかいないため長い間、エリアスケーリングの実態が公表されずに、DTCO(Design Technology Co-Optimization)という言葉で表現されてきた。
筆者もこの7nm、5nmの謎を解明するのに実は約1年近くかかった。日本のラピダスが2nmプロセスと呼んでいる技術ノードも同様で、配線幅と間隔が2nmでは決してない。3方向からドレイン-ソースの空乏層を閉じ込めてリーク電流を減らす、これまでのFinFETから、4方向から空乏層を閉じ込めるGAA(Gate All Around)構造のトランジスタに変えて2nmプロセスとIBM研究所が称しているだけにすぎない。実際の最小寸法はこれまでで最も小さい11nm程度にとどまるだろう。この加工寸法の実現にはやはりEUVのダブルパターニング技術が使われることになるだろう。